目录
并查集
题解来源
标了🤦♂️🤦♂️的是完全按照大佬们的题解写的
标了🌟的是理解了大神们的题解后,自己又写的
没标的是自己磕磕绊绊写出来的低水平代码
自己写个模板
cpp// parent是每个点的祖宗结点
// size只对祖宗结点有意义,保存该区间内点的数量
vector<int> parent, size;
void initUnion(int len){
parent.resize(len);
size.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
size[i] = 1;
}
}
int find(int x){
if(x != parent[x]){ // 路径压缩,视情况添加
parent[x] = find(parent[x]);
}
return parent[x];
}
int getSize(int x){
return size[find(x)];
}
void merge(int a, int b){ // 可以手动指定特定区间的祖宗结点,见130题
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
size[pa] += size[pb];
}
核心思想 并查集的实现方式中可以改变的几个地方 路径压缩、统计每个集合中元素的个数、记录最大集合元素个数 要灵活使用map、set等数据结构来降低时间复杂度 关于地图,砖块,网格的题目,可以新建一个特殊节点,将四周边缘的砖块或者网格都 union() 到这个特殊节点上。 PS: 并查集是目前练过最难的题目了 并查集的难度不在构造并查集;而在思路,我们要想出来,用什么构造并查集,构造之后要如何使用 可能还是练得少,做这种题没什么思路,但看一眼题解思路就立马会做了 只能说构造难度和逻辑难度都低,但解题思路是需要大量练习(或者是天赋异禀)才能有 10道并查集的练习题,只有两道是纯自己写的 慢慢训练解题思维!
题目
128. 最长连续序列
难度:中等
题目:
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例:
输入:nums = [100,4,200,1,3,2] 输出:4 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
输入:nums = [0,3,7,2,5,8,4,6,0,1] 输出:9
提示:
0 <= nums.length <= 105-109 <= nums[i] <= 109
解题思路:
- 因为要找出最长的子区间,所以我们除了要维护一个
parent数组,还要维护一个size数组用来存放每个子区间的大小 - 首先初始化并查集,每个元素的祖宗结点都是自身
- 遍历
nums,用map存储每一个元素num- 先在
map中寻找有没有num+1和num-1,因为num可以和这两个数据合并成一个子区间 - 如果有,就合并两个元素所在的区间
- 如果没有,就继续遍历直至结束
- 先在
- 最后从
size数组中找到最大的子区间长度返回即可
代码:
cppclass Solution {
public:
vector<int> parent, size;
int find(int x){ // 找到祖宗结点
if (parent[x] != x){ // 做路径压缩
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){ // 合并两个区间,将b并到a上
parent[find(b)] = find(a);
size[find(a)] = size[find(a)] + size[find(b)];
}
void initUnion(int length){ // 初始化并查集
parent.resize(length);
size.resize(length);
for(int i = 0; i < length; i ++){
parent[i] = i;
size[i] = 1;
}
}
int getMaxSize(int length){ // 获得最长子区间
int maxSize = 0;
for(int i = 0; i < length; i ++){
maxSize = max(maxSize, size[i]);
}
return maxSize;
}
int longestConsecutive(vector<int>& nums) {
int length = nums.size();
if(length == 0){
return 0;
}
initUnion(length);
map<int, int> mapnums;
for(int i = 0; i < length; i ++){ // 合并
if(mapnums.find(nums[i]) != mapnums.end()){
continue;
}
if(mapnums.find(nums[i] + 1) != mapnums.end()){
merge(i, mapnums[nums[i] + 1]);
}
if(mapnums.find(nums[i] - 1) != mapnums.end()){
merge(i, mapnums[nums[i] - 1]);
}
mapnums.insert({nums[i], i});
}
return getMaxSize(length);
}
};
130. 被围绕的区域 🌟
难度:中等
题目:
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例:
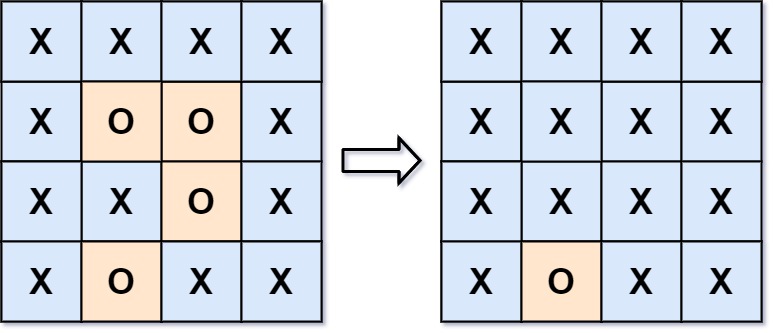
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] 输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] 解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
输入:board = [["X"]] 输出:[["X"]]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j]为'X'或'O'
解题思路:
O有两种存在状态- 状态一:被X围绕
- 状态二:与边界相连,不被X围绕
- 那么我们通过并查集将这两种状态的
O区分出来 - 定义一个公共的祖宗结点
flag,将所有的边界O全部合并到flag上 - 当我们在矩阵内部进行遍历时,遇到两个相连的
O,合并且判断是否有祖宗结点为flag的点,如果有,则另一个O点也合并到flag上,这样就可以保证所有与边界相连的O点的祖宗结点均为flag - 最终遍历矩阵,如果
O点的祖宗结点为flag,将其改为X
代码:
cppclass Solution {
public:
vector<int> parent;
int flag;
void initUnion(int len){
parent.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
if(pa == flag){ // 手动维持祖宗结点为flag
parent[pb] = pa;
}
else{
parent[pa] = pb;
}
}
void solve(vector<vector<char>>& board) {
int m = board.size();
int n = board[0].size();
flag = m * n;
initUnion(m * n + 1);
for(int i = 0; i < m; i ++){
for(int j = 0; j < n; j ++){
if(board[i][j] == 'X'){
continue;
}
if(i == 0 || j == 0 || i == m - 1 || j == n - 1){
merge(m * n, i * n + j);
}
if(i > 0 && board[i - 1][j] == 'O'){ // 只需要判断上边和左边的原因:这两个方向的元素已经被判断过了
merge((i - 1) * n + j, i * n + j);
}
if(j > 0 && board[i][j - 1] == 'O'){
merge(i * n + j - 1, i * n + j);
}
}
}
for(int i = 0; i < m; i ++){ // 找到祖宗结点不为flag的 O , 将其修改为 X
for(int j = 0; j < n; j ++){
if(board[i][j] == 'O' && find(i * n + j) != flag){
board[i][j] = 'X';
}
}
}
}
};
721. 账户合并 🤦♂️🤦♂️
难度:中等
题目:
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例:
输入:accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]] 输出:[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]] 解释: 第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。 第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。 可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'], ['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
输入:accounts = [["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"],["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"],["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"],["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"],["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"]] 输出:[["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"],["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"],["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"],["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"],["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"]]
提示:
1 <= accounts.length <= 10002 <= accounts[i].length <= 101 <= accounts[i][j].length <= 30accounts[i][0]由英文字母组成accounts[i][j] (for j > 0)是有效的邮箱地址
解题思路:
- 这道题的逻辑部分是完全看官方题解的,主要是自己开始没有使用引用,一直超时,看了官方题解,把所有的定义变量都变成了引用,才勉强通过
- 其实整体逻辑是不难的
- 首先我们维护两个
map用来存放email和name、index的对应关系;用emailsCount来记录总的email数量 - 因为在两个
map中我们都是用email作为键值,而键值不能重复,因此在维护的并查集里,也要用无重复的email数量来初始化,即emailsCount - 初始化并查集之后,对
accounts进行遍历,对于accounts中的每一个元素account,我们要将其中的所有email都放入同一个子区间,这样我们就得到了合并后的并查集,同一个人的所有账户都被放入了同一个子区间 - 之后我们再维护一个
map来存放index和emails的对应关系,每个email都有唯一的祖宗结点,其索引就是index- 通过从
emailToIndex中不断取出email,找到该email的祖宗结点索引index后,加到indexToEmails[index]中
- 通过从
- 从而我们得到了
index和index对应的所有emails,也就是每个人的所有账户都已经放到了一起 - 题目要求按照
ASCII顺序返回,做一个sort即可 - 随便拿到一个
email,从emailToName中得到name,再和emails一起作为vector<string>类型的数据压入最终的res - 返回
res
- 首先我们维护两个
代码:
cppclass Solution {
public:
vector<int> parent;
int find(int x){ // 找到祖宗结点
if (parent[x] != x){ // 做路径压缩
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){ // 合并两个区间,将a并到b上
parent[find(b)] = find(a);
}
void initUnion(int length){ // 初始化并查集
parent.resize(length);
for(int i = 0; i < length; i ++){
parent[i] = i;
}
}
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
// 首先用两个map来存储 emailToName 和 emailToIndex
// 分别为email对应的name和email对应的编号
map<string, int> emailToIndex;
map<string, string> emailToName;
// 用emailCount来存储email的编号
int emailsCount = 0;
// 生成emailToName和emailToIndex
for (auto& account : accounts) {
string& name = account[0];
int length = account.size();
for (int i = 1; i < length; i ++) {
string& email = account[i];
if (!emailToName.count(email)) {
emailToIndex[email] = emailsCount++;
emailToName[email] = name;
}
}
}
// 初始化并查集
initUnion(emailsCount);
// 合并并查集
for(auto& account: accounts){
string& preEmail = account[1];
int preIndex = emailToIndex[preEmail];
int length = account.size();
for (int i = 2; i < length; i ++) {
string& nextEmail = account[i];
int nextIndex = emailToIndex[nextEmail];
merge(preIndex, nextIndex);
}
}
// 构建indexToEmails,使得我们可以通过index来获取所有的email
map<int, vector<string>> indexToEmails;
for (auto& iter : emailToIndex) {
int index = find(iter.second);
vector<string>& account = indexToEmails[index];
account.emplace_back(iter.first);
indexToEmails[index] = account;
}
// 构建返回数组
vector<vector<string>> res;
for (auto& iter : indexToEmails) {
sort(iter.second.begin(), iter.second.end());
string& name = emailToName[iter.second[0]];
vector<string> account;
account.emplace_back(name);
for (auto& email : iter.second) {
account.emplace_back(email);
}
res.emplace_back(account);
}
return res;
}
};
765. 情侣牵手
难度:困难
题目:
n 对情侣坐在连续排列的 2n 个座位上,想要牵到对方的手。
人和座位由一个整数数组 row 表示,其中 row[i] 是坐在第 i 个座位上的人的 ID。情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后一对是 (2n-2, 2n-1)。
返回 最少交换座位的次数,以便每对情侣可以并肩坐在一起。 每次交换可选择任意两人,让他们站起来交换座位。
示例:
输入: row = [0,2,1,3] 输出: 1 解释: 只需要交换row[1]和row[2]的位置即可。
输入: row = [3,2,0,1] 输出: 0 解释: 无需交换座位,所有的情侣都已经可以手牵手了。
提示:
2n == row.length2 <= n <= 30n是偶数0 <= row[i] < 2nrow中所有元素均无重复
解题思路:
- 当我们想要让一对情侣坐在一起的时候,一共会影响四个人的位置关系
- 例如,ab坐在一起,cd坐在一起,当我们想要让ac坐在一起时,调整的结果就是ac和bd
- 那么我们就可以得到4个人最多交换一次就可以满足条件;6个人最多交换2次就可以满足条件,以此类推
- 结合并查集,初始情况中,一个子区间有两个人,假设共两个子区间,想要满足条件,至多需要交换一次座位,即合并一次子区间;三个子区间至多合并两次;以此类推
- 整体逻辑
- 首先初始化并查集
- 做第一步合并:让每一对情侣在同一个子区间,即(0,1)(2,3)……
- 第二步合并:
- 遍历nums,两两一组
- 检查nums[i]和nums[i + 1]是否在同一个区间,不在就合并,在就继续遍历
- 统计合并次数
- 返回合并次数
代码:
cppclass Solution {
public:
vector<int> parent;
void initUnion(int length){
parent.resize(length);
for(int i = 0; i < length; i ++){
parent[i] = i;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
parent[find(b)] = find(a);
}
int minSwapsCouples(vector<int>& row) {
int length = row.size();
initUnion(length);
int count = 0;
int i = 0;
while(i < length){ // 先将每一对情侣放入一个子区间
merge(i, i + 1);
i = i + 2;
}
i = 0;
while(i < length){ // 从头到尾两两遍历,如果当前一对不是一个区间的,那么就把他们所在区间合并,并记录合并次数
if(find(row[i]) != find(row[i + 1])){
merge(row[i], row[i + 1]);
count++;
}
i = i + 2;
}
return count;
}
};
778. 水位上升的泳池中游泳 🌟
难度:困难
题目:
在一个 n x n 的整数矩阵 grid 中,每一个方格的值 grid[i][j] 表示位置 (i, j) 的平台高度。
当开始下雨时,在时间为 t 时,水池中的水位为 t 。你可以从一个平台游向四周相邻的任意一个平台,但是前提是此时水位必须同时淹没这两个平台。假定你可以瞬间移动无限距离,也就是默认在方格内部游动是不耗时的。当然,在你游泳的时候你必须待在坐标方格里面。
你从坐标方格的左上平台 (0,0) 出发。返回 你到达坐标方格的右下平台 (n-1, n-1) 所需的最少时间 。
示例:
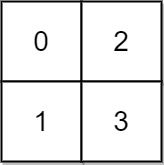
输入: grid = [[0,2],[1,3]] 输出: 3 解释: 时间为0时,你位于坐标方格的位置为 (0, 0)。 此时你不能游向任意方向,因为四个相邻方向平台的高度都大于当前时间为 0 时的水位。 等时间到达 3 时,你才可以游向平台 (1, 1). 因为此时的水位是 3,坐标方格中的平台没有比水位 3 更高的,所以你可以游向坐标方格中的任意位置
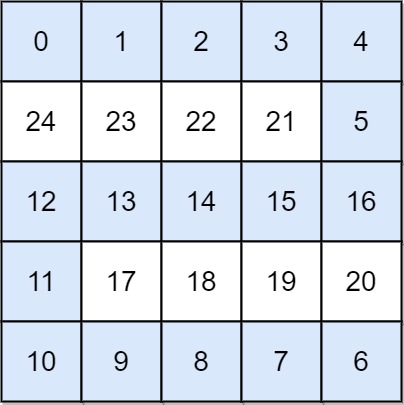
输入: grid = [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]] 输出: 16 解释: 最终的路线用加粗进行了标记。 我们必须等到时间为 16,此时才能保证平台 (0, 0) 和 (4, 4) 是连通的
提示:
n == grid.lengthn == grid[i].length1 <= n <= 500 <= grid[i][j] < n2grid[i][j]中每个值 均无重复
解题思路:
- 这道题解法的妙处在于,
t秒的水位为t,那么我们找到高度为t的平台,查看该平台周围的四个方向, 是否有高度低于t的,如果有,就合并为一个区间 - 高度从低到高遍历平台,保证符合当前水位的平台一定都被遍历过,且建立了正确的子区间
- 当在遍历过程中发现,
(0, 0)和(n-1, n-1)平台在同一区间内,则返回水位即可
代码:
cppclass Solution {
public:
int sideLength;
vector<pair<int, int>> directions{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
vector<int> parent;
int getIndex(int i, int j){
return i * sideLength + j;
}
void initUnion(int len){
parent.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
parent[find(b)] = find(a);
}
int swimInWater(vector<vector<int>>& grid) {
sideLength = grid.size();
int allLength = sideLength * sideLength;
int index[allLength];
for(int i = 0; i < sideLength; i ++){ // 将每个位置的高度和坐标对应存入index
for(int j = 0; j < sideLength; j ++){
index[grid[i][j]] = getIndex(i, j);
}
}
initUnion(allLength);
for(int i = 0; i < allLength; i ++){
// 获取和当前水位高度相同点的坐标
int x = index[i] / sideLength;
int y = index[i] % sideLength;
for(const auto& dir: directions){
// 获取新的点
int newx = x + dir.first, newy = y + dir.second;
// 判断是否满足条件:是否在矩阵内 && 高度是否低于水位
if(newx >= 0 && newx < sideLength && newy >= 0 && newy < sideLength && grid[newx][newy] <= i){
merge(index[i], getIndex(newx, newy));
}
if(find(0) == find(allLength - 1)){
return i;
}
}
}
return -1;
}
};
803. 打砖块 🌟
难度:困难
题目:
有一个 m x n 的二元网格 grid ,其中 1 表示砖块,0 表示空白。砖块 稳定(不会掉落)的前提是:
- 一块砖直接连接到网格的顶部,或者
- 至少有一块相邻(4 个方向之一)砖块 稳定 不会掉落时
给你一个数组 hits ,这是需要依次消除砖块的位置。每当消除 hits[i] = (rowi, coli) 位置上的砖块时,对应位置的砖块(若存在)会消失,然后其他的砖块可能因为这一消除操作而 掉落 。一旦砖块掉落,它会 立即 从网格 grid 中消失(即,它不会落在其他稳定的砖块上)。
返回一个数组 result ,其中 result[i] 表示第 i 次消除操作对应掉落的砖块数目。
注意,消除可能指向是没有砖块的空白位置,如果发生这种情况,则没有砖块掉落。
示例:
输入:grid = [[1,0,0,0],[1,1,1,0]], hits = [[1,0]] 输出:[2] 解释:网格开始为: [[1,0,0,0], [1,1,1,0]] 消除 (1,0) 处加粗的砖块,得到网格: [[1,0,0,0] [0,1,1,0]] 两个加粗的砖不再稳定,因为它们不再与顶部相连,也不再与另一个稳定的砖相邻,因此它们将掉落。得到网格: [[1,0,0,0], [0,0,0,0]] 因此,结果为 [2] 。
输入:grid = [[1,0,0,0],[1,1,0,0]], hits = [[1,1],[1,0]] 输出:[0,0] 解释:网格开始为: [[1,0,0,0], [1,1,0,0]] 消除 (1,1) 处加粗的砖块,得到网格: [[1,0,0,0], [1,0,0,0]] 剩下的砖都很稳定,所以不会掉落。网格保持不变: [[1,0,0,0], [1,0,0,0]] 接下来消除 (1,0) 处加粗的砖块,得到网格: [[1,0,0,0], [0,0,0,0]] 剩下的砖块仍然是稳定的,所以不会有砖块掉落。 因此,结果为 [0,0] 。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 200grid[i][j]为0或11 <= hits.length <= 4 * 104hits[i].length == 20 <= xi <= m - 10 <= yi <= n - 1- 所有
(xi, yi)互不相同
解题思路:
- 逆向思维,并查集是合并区间,但这道题是分离区间;那么我们只需要把分离逆向为合并即可
- 主要逻辑
- 定义tempGrid来存放完全分离后的区间,即将消除掉的地方全部置为0
- 初始化并查集,并根据最初的tempGrid来建立并查集
- 定义一个roof来作为屋顶结点,最顶层的砖块首先和屋顶连为一个整体,代表最初始的稳定区间
- 其次遍历其他层的砖块,建立相应的区间
- 从后往前遍历消除砖块,填补空缺后,观察有无子区间可以合并
- 如果在grid中的位置是空,那么直接压入0即可,一定没有砖块受影响
- 合并的主从位置不影响最后操作
- 定义getSize()函数来获取每个元素所在区间的元素个数,因此不受主从位置的影响
- 最终返回res即可
- 官方题解很详细,可以查看
- 踩的坑就是,一定要定义getSize()函数,我开始尝试用roof一直作为根结点,后来发现没办法全面考虑,总会有情况导致根结点发生变化,致使最终结果出错。getSize()函数可以保证一定是返回了祖宗结点的size值
代码:
cppclass Solution {
public:
int row, col;
vector<int> parent, size;
vector<pair<int, int>> directions{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
int getIndex(int i, int j){
return i * col + j;
}
bool inGrid(int i, int j){
return i >= 0 && i < row && j >= 0 && j < col;
}
void initUnion(int len){
parent.resize(len);
size.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
size[i] = 1;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
size[pa] += size[pb];
}
int getSize(int x){ // 很重要,因为有可能根结点会变成其他的点,但区间总和不会变
return size[find(x)];
}
vector<int> hitBricks(vector<vector<int>>& grid, vector<vector<int>>& hits) {
vector<int> res;
row = grid.size();
col = grid[0].size();
int tempGrid[row][col];
int length = hits.size();
int roof = row * col;
// 初始化tempGrid,将需要击碎的地方变为0
for(int i = 0; i < row; i ++){ // 将grid赋给tempGrid
for(int j = 0; j < col; j ++){
tempGrid[i][j] = grid[i][j];
}
}
for(int i = 0; i < length; i ++){ // 将对应位置变为0
tempGrid[hits[i][0]][hits[i][1]] = 0;
}
// 建立并查集并初始化
initUnion(roof + 1); // 多出来的一个空间给屋顶,屋顶为一个整体
for(int i = 0; i < col; i ++){
if(tempGrid[0][i] == 1){ // 将最上面的砖块和屋顶放入一个子区间
merge(roof, i);
}
}
for(int i = 1; i < row; i ++){ // 对于其余砖块,判断上边和左边是否为砖块
for(int j = 0; j < col; j ++){
if(tempGrid[i][j] == 1){
if(tempGrid[i - 1][j] == 1){
merge(getIndex(i - 1, j), getIndex(i, j));
}
if(j > 0 && tempGrid[i][j - 1] == 1){
merge(getIndex(i, j - 1), getIndex(i, j));
}
}
}
}
// 不断添加砖块,修改返回值
for(int i = length - 1; i >= 0; i --){
int x = hits[i][0], y = hits[i][1]; // 拿到坐标
if(grid[x][y] == 1){
int tempSize = getSize(roof);
if(x == 0){ // 把上方是屋顶的情况先判断了
merge(roof, y);
}
for(const auto& dir: directions){
// 获取新的点
int newx = x + dir.first, newy = y + dir.second;
// 判断是否满足条件:是否在矩阵内 && 是否是砖块
if(inGrid(newx, newy) && tempGrid[newx][newy] == 1){
merge(getIndex(newx, newy), getIndex(x, y));
}
}
int nowSize = getSize(roof);
res.push_back(max(0, nowSize - tempSize - 1));
tempGrid[x][y] = 1;
}
else{
res.push_back(0);
}
}
reverse(res.begin(), res.end());
return res;
}
};
924. 尽量减少恶意软件的传播 🌟
难度:困难
题目:
给定一个由 n 个节点组成的网络,用 n x n 个邻接矩阵 graph 表示。在节点网络中,只有当 graph[i][j] =1 时,节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
如果从 initial 中移除某一节点能够最小化 M(initial), 返回该节点。如果有多个节点满足条件,就返回索引最小的节点。**
请注意,如果某个节点已从受感染节点的列表 initial 中删除,它以后仍有可能因恶意软件传播而受到感染。
示例:
输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] 输出:0
输入:graph = [[1,0,0],[0,1,0],[0,0,1]], initial = [0,2] 输出:0
输入:graph = [[1,1,1],[1,1,1],[1,1,1]], initial = [1,2] 输出:1
提示:
n == graph.lengthn == graph[i].length2 <= n <= 300graph[i][j]是0或1.graph[i][j] == graph[j][i]graph[i][i] == 11 <= initial.length < n0 <= initial[i] <= n - 1initial中每个整数都不同
解题思路:
-
首先建立并查集,合并相连接点
-
对于每个污染点来说,统计其所在子区间中的污染点个数
-
如果,该区间污染点个数大于
1,则删除污染点无意义- 因为只能删除一个污染点,而删除后,该区间依然会被其他点污染
-
反之,污染点个数为
1,则可以删除 -
最终返回
res
代码:
cppclass Solution {
public:
vector<int> parent,size;
void initUnion(int len){
parent.resize(len);
size.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
size[i] = 1;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
size[pa] += size[pb];
}
int getSize(int x){
return size[find(x)];
}
int minMalwareSpread(vector<vector<int>>& graph, vector<int>& initial) {
int n = graph.size();
initUnion(n);
for(int i = 0; i < n; i ++){ // 合并所有的相连点
for(int j = 0; j < n; j ++){
if(graph[i][j] == 1){
merge(i, j);
}
}
}
vector<int> count(n, 0);
for(int dirty: initial){ // 统计,每个污染点所在的子区间内,有多少个污染点
count[find(dirty)] ++;
}
int tempSize = -1, res = -1;
for(int dirty: initial){
int pdirty = find(dirty);
if(count[pdirty] == 1){ // 如果该区间内,污染点大于1个,则删除无意义
int tempSize1 = size[pdirty];
if(tempSize1 > tempSize || (tempSize1 == tempSize && dirty < res)){
tempSize = tempSize1;
res = dirty;
}
}
}
if(res == -1){ // 如果所有的污染点删除均无意义,就返回最小点
res = *min_element(initial.begin(), initial.end());
}
return res;
}
};
928. 尽量减少恶意软件的传播II 🌟
难度:困难
题目:
给定一个由 n 个节点组成的网络,用 n x n 个邻接矩阵 graph 表示。在节点网络中,只有当 graph[i][j] =1 时,节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
我们可以从 initial 中删除一个节点,并完全移除该节点以及从该节点到任何其他节点的任何连接。
请返回移除后能够使 M(initial) 最小化的节点。如果有多个节点满足条件,返回索引 最小的节点 。
示例:
输出:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] 输入:0
输入:graph = [[1,1,0],[1,1,1],[0,1,1]], initial = [0,1] 输出:1
输入:graph = [[1,1,0,0],[1,1,1,0],[0,1,1,1],[0,0,1,1]], initial = [0,1] 输出:1
提示:
n == graph.lengthn == graph[i].length2 <= n <= 300graph[i][j]是0或1.graph[i][j] == graph[j][i]graph[i][i] == 11 <= initial.length < n0 <= initial[i] <= n - 1initial中每个整数都不同
解题思路:
-
和 924题 的区别在于
- 本题完全删除了所有连接,可视为该点不存在
- 而924题只是将初始状态改为未污染,后续依然可以进入整体的逻辑操作中
- 因此,924可以直接连接所有相连点,统计每个污染点所在区间的大小
- 而对于本题,完全删除结点有可能将大区间分为两部分,因此只能对未污染点建立子区间
-
首先对初始的未污染点构建并查集,将未污染点合并为多个子区间
-
对于删除污染点
- 如果一个子区间和多个污染点相连,那删除污染点是无意义的。删了一个,其他污染点依然可以将区间内的所有点都污染了
- 如果一个子区间只和一个污染点相连,那么删除该污染点后,该区间就都可以幸存,可以减少
M(initial)
-
因此我们统计对于每个污染点,可以到达的所有未污染子区间,即
graph[dirty][clean] = 1,获得find(clean) -
将所有区间的祖宗结点放入同一个
set中,并和对应的污染点压入map中,构成key-value -
同时我们要统计对于所有的祖宗结点,有多少污染点可以到达它们,也就是
count[i] -
最后,遍历
map,取出污染点和set,判断能否移除当前污染点,计算tempSize和res
代码:
cppclass Solution {
public:
vector<int> parent, size;
void initUnion(int len){
parent.resize(len);
size.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
size[i] = 1;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
int getSize(int x){
return size[find(x)];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
size[pa] += size[pb];
}
int minMalwareSpread(vector<vector<int>>& graph, vector<int>& initial) {
int n = graph.size();
initUnion(n);
// 第一步,将初始没有被污染的点建立并查集
vector<int> cleanNode(n, 1); // 未污染点,初始值为1
for(int num: initial){ // 将被污染点的对应位置变为0
cleanNode[num] = 0;
}
for(int i = 0; i < n; i ++){ // 合并未污染区间
if(cleanNode[i] == 1){
for(int j = 0; j < n; j ++){
if(cleanNode[j] == 1 && graph[i][j] == 1){
merge(i, j);
}
}
}
}
// 第二步,统计每个污染点可以到达的未污染点区间;并记录每个未污染区间可以被多少污染点到达
vector<int> count(n, 0); // 可到达未污染区间的污染点个数,初始值为0
map<int, set<int>> dirtyToClean; // 污染点到未污染区间的map
for(int dirty: initial){ // 遍历污染点
set<int> toClean;
for(int clean = 0; clean < n; clean ++){ // 记录该污染点可以到达的未污染区间
if(cleanNode[clean] == 1 && graph[dirty][clean] == 1){
toClean.insert(find(clean));
}
}
dirtyToClean.insert({dirty, toClean}); // 将污染点和对应的可到达区间压入map
for(int clean :toClean){ // 统计可到达的个数
count[clean]++;
}
}
// 第三步,找到只能被一个污染点到达的未污染区间,该污染点删除后,整个区间都能够不被污染
int tempSize = -1, res = -1;
for(auto iter : dirtyToClean) { // 遍历所有污染点和可到达的未污染区间
set<int> toClean = iter.second;
int tempSize1 = 0;
for(int clean: toClean){
if(count[clean] == 1){ // 如果该区间只有一个污染点可以到达,则删除污染点有意义
tempSize1 += getSize(clean);
}
}
if(tempSize1 > tempSize || (tempSize1 == tempSize && iter.first < res)){ // 判断tempsize和res
tempSize = tempSize1;
res = iter.first;
}
}
return res;
}
};
952. 按公因数计算最大组件大小
难度:困难
题目:
给定一个由不同正整数的组成的非空数组 nums ,考虑下面的图:
- 有
nums.length个节点,按从nums[0]到nums[nums.length - 1]标记; - 只有当
nums[i]和nums[j]共用一个大于 1 的公因数时,nums[i]和nums[j]之间才有一条边。
返回 图中最大连通组件的大小 。
示例:
输入:nums = [4,6,15,35] 输出:4
输入:nums = [20,50,9,63] 输出:2
输入:nums = [2,3,6,7,4,12,21,39] 输出:8
提示:
1 <= nums.length <= 2 * 1041 <= nums[i] <= 105nums中所有值都 不同
解题思路:
- 对nums[i]上限定义并查集,即大小为100001
- 通过埃式筛法筛选出在nums[i]范围内的所有素数
- 用这些素数来找出nums[i]范围内所有的合数
- 将对应素数和找到的合数进行区间合并
- 要注意的是,如果该素数没有出现在nums中,那么要将size[i]变为0,防止影响最终结果个数
- 最后从nums中找到拥有最多元素的子区间并返回个数
- 不能采用线性筛法,因为对于线性筛法,每个数只被它的最小质因子筛掉,不会出现重复筛除的情况,导致本来应该合并的区间没有合并,影响最终结果
代码:
cppclass Solution {
public:
vector<int> parent, size;
void initUnion(int len){
parent.resize(len);
size.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
size[i] = 1;
}
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
int getSize(int x){
return size[find(x)];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
size[pa] += size[pb];
}
int largestComponentSize(vector<int>& nums) {
initUnion(100001); // 初始化并查集
vector<int> prime(100001, 1); // 初始化素数
set<int> s;
for(int i = 0; i < nums.size(); i ++){ // 将nums放入s中,方便后续判断是否存在并取出最大值
s.insert(nums[i]);
}
int top = *s.rbegin(); // 获得最大值
for(int i = 2; i <= top; i++){
if(prime[i]){
if(!s.count(i)){ // 如果该素数在s中不存在,那么要将size变为0,否则会在最终的getSize中加上不存在的素数个数
size[i] = 0;
}
for (int j = i + i; j <= top; j += i){ // 只对素数筛倍数,降低时间复杂度
prime[j] = 0;
if(s.count(j)){ // 如果该合数存在,合并子区间
merge(i, j);
}
}
}
}
int res = 0;
for(int num:nums){ // 找到最大的子区间
res = max(res, getSize(num));
}
return res;
}
};
959. 由斜杠划分区域 🌟
难度:中等
题目:
在由 1 x 1 方格组成的 n x n 网格 grid 中,每个 1 x 1 方块由 '/'、'\' 或空格构成。这些字符会将方块划分为一些共边的区域。
给定网格 grid 表示为一个字符串数组,返回 区域的数量 。
请注意,反斜杠字符是转义的,因此 '\' 用 '\\' 表示。
示例:
.png)
输入:grid = [" /","/ "] 输出:2
.png)
输入:grid = [" /"," "] 输出:1
.png)
输入:grid = ["/\\","\\/"] 输出:5 解释:回想一下,因为 \ 字符是转义的,所以 "/\\" 表示 /\,而 "\\/" 表示 \/。
提示:
n == grid.length == grid[i].length1 <= n <= 30grid[i][j]是'/'、'\'、或' '
解题思路:
- 将每个元素看做一个正方形,正方形可以由四个三角形组成;而斜杠可以将四个三角形划分为两个子区间
- 从而我们构建 4 * n * n 的并查集,尝试将每个三角形所在区间进行合并
- 正方形内部合并
- 如果
grid[i][j] = '/',则合并三角形 0 3、1 2 为两个子区间 - 如果
grid[i][j] = '\\',则合并三角形 0 1、2 3 为两个子区间 - 如果
grid[i][j] = ' ',则四个三角形合并为一个子区间
- 如果
- 正方形之间合并
- 每个正方形都与右边、下边的正方形进行区间合并
- 和右边:合并 1 3
- 和下边:合并 2 0
- 最终判断并查集中区间数量即可
代码:
cppclass Solution {
public:
vector<int> parent;
int count;
void initUnion(int len){
parent.resize(len);
for(int i = 0; i < len; i ++){
parent[i] = i;
}
count = len;
}
int find(int x){
if(x != parent[x]){
parent[x] = find(parent[x]);
}
return parent[x];
}
void merge(int a, int b){
int pa = find(a), pb = find(b);
if(pa == pb){
return;
}
parent[pb] = pa;
count --;
}
int regionsBySlashes(vector<string>& grid) {
int length = grid.size();
initUnion(4 * length * length);
for(int i = 0; i < length; i ++){
string& temp = grid[i];
for(int j = 0; j < length; j ++){
int index = 4 * ( i * length + j); // 每个正方形内,序号为0的三角形下标
// 正方形内部合并
if(temp[j] == '/'){
merge(index, index + 3);
merge(index + 1, index + 2);
}
else if(temp[j] == '\\'){
merge(index, index + 1);
merge(index + 2, index + 3);
}
else{
merge(index, index + 1);
merge(index, index + 2);
merge(index, index + 3);
}
// 正方形之间合并
if(j + 1 < length){ // 向右合并,1 和 3
merge(index + 1, index + 7);
}
if(i + 1 < length){ // 向下合并,2 和 0
merge(index + 2, 4 * ( (i + 1) * length + j));
}
}
}
return count;
}
};
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!