目录
回溯
题解来源
标了🤦♂️🤦♂️的是完全按照大佬们的题解写的
标了🌟的是理解了大神们的题解后,自己又写的
没标的是自己磕磕绊绊写出来的低水平代码
自己写个模板
cpp// 排列问题
class Solution {
public:
T res; // 定义返回值
bool status[N]; // 定义状态数组,记录可用情况
void dfs(T nums){
if(check){ // 判断是否满足条件
// 做相关逻辑操作
return;
}
for(int i = 0; i < nums.size(); i ++){ // 排列问题,从头开始遍历
if(check1){ // 判断当前元素是否可用,判断是否满足题目条件
continue;
}
if(!status[i]){ // 如果该字母可用
status[i] = true; // 改变状态
// 做相关逻辑操作
dfs(tiles); // 进入新一轮遍历
// 做上一步的逆操作,恢复
status[i] = false; // 恢复状态
}
}
}
int functionMain(T nums) {
// sort(nums.begin(), nums.end()); // 如果有去重需求就对nums进行排序,让字母有序,方便后续遍历去重
dfs(nums); // 进入遍历
return res; // 返回res
}
};
cpp// 组合问题
class Solution {
public:
T res; // 定义返回值
bool status[N]; // 定义状态数组,记录可用情况
void dfs(T nums, int position){ // position为当前遍历到的位置
if(check){ // 判断是否满足条件
// 做相关逻辑操作
return;
}
for(int i = position; i < nums.size(); i ++){ // 排列问题,从头开始遍历
if(check1){ // 判断当前元素是否可用,判断是否满足题目条件
continue;
}
if(!status[i]){ // 如果该字母可用
status[i] = true; // 改变状态
// 做相关逻辑操作
dfs(tiles, i + 1); // 进入新一轮遍历,对position的参数做修改
// 做上一步的逆操作,恢复
status[i] = false; // 恢复状态
}
}
}
int functionMain(T nums) {
// sort(nums.begin(), nums.end()); // 如果有去重需求就对nums进行排序,让字母有序,方便后续遍历去重
dfs(nums); // 进入遍历
return res; // 返回res
}
};
回溯三部曲 1. 判断是否结束遍历+逻辑操作 2. 进入循环 2.1 判断是否满足可遍历条件 2.2 修改状态并进入新一轮 2.3 恢复状态 3. 结束dfs函数
题目
37. 解数独 🌟
难度:困难
题目:
编写一个程序,通过填充空格来解决数独问题。
数独的解法需 遵循如下规则:
- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
数独部分空格内已填入了数字,空白格用 '.' 表示。
示例:

输入:board = [["5","3",".",".","7",".",".",".","."], ["6",".",".","1","9","5",".",".","."], [".","9","8",".",".",".",".","6","."], ["8",".",".",".","6",".",".",".","3"], ["4",".",".","8",".","3",".",".","1"], ["7",".",".",".","2",".",".",".","6"], [".","6",".",".",".",".","2","8","."], [".",".",".","4","1","9",".",".","5"], [".",".",".",".","8",".",".","7","9"]] 输出:[["5","3","4","6","7","8","9","1","2"], ["6","7","2","1","9","5","3","4","8"], ["1","9","8","3","4","2","5","6","7"], ["8","5","9","7","6","1","4","2","3"], ["4","2","6","8","5","3","7","9","1"], ["7","1","3","9","2","4","8","5","6"], ["9","6","1","5","3","7","2","8","4"], ["2","8","7","4","1","9","6","3","5"], ["3","4","5","2","8","6","1","7","9"]] 解释:输入的数独如上图所示,唯一有效的解决方案如下所示:

提示:
board.length == 9board[i].length == 9board[i][j]是一位数字或者'.'- 题目数据 保证 输入数独仅有一个解
解题思路:
- 解数独相当于一个可以不走到尽头的dfs
- 对于常规的dfs题目,我们需要将所有可能的情况遍历一次,找全排列
- 而对于解数独,我们只需要求出一种解法就可以了,因此需要维护一个notcontinue来判断是否跳出循环
- 题目要从三方面判断是否可用,即:
- 当前行是否可用数字x,即
line[i][x]是否为false - 当前列是否可用数字x,即
column[j][x]是否为false - 当前九宫格是否可用数字x,即
block[i/3][j/3][x]是否为false
- 当前行是否可用数字x,即
- 因此每次都需要判断三种情况:
if(!line[i][k] && !column[j][k] && !block[i / 3][j / 3][k]) - 剩下的就是传统dfs的内容了
代码:
cppclass Solution {
public:
bool line[9][9]; // 记录行中数字是否可存放
bool column[9][9]; // 记录列中数字是否可存放
bool block[3][3][9]; // 记录九宫格内数字是否可存放
bool notcontinue; // 记录是否需要继续遍历
vector<pair<int,int>> emptyspaces; // 记录需要存放数字的地方
void dfs(vector<vector<char>>& board, int depth){
if(depth == emptyspaces.size()){ // 如果将需要存放数字的地方遍历完成,结束循环
notcontinue = true;
return;
}
auto [i, j] = emptyspaces[depth]; // 获取数字存放地点
for(int k = 0; k < 9 && !notcontinue; k ++){
if(!line[i][k] && !column[j][k] && !block[i / 3][j / 3][k]){ // 如果当前位置可以存放
line[i][k] = column[j][k] = block[i / 3][j / 3][k] = true; // 修改状态为不可用
board[i][j] = k + '0' + 1; // 改变board对应位置
dfs(board, depth + 1); // 在当前修改的基础上继续dfs
line[i][k] = column[j][k] = block[i / 3][j / 3][k] = false; // 修改状态为可用
}
}
}
void solveSudoku(vector<vector<char>>& board) {
for(int i = 0; i < board.size(); i ++){ // 遍历board得到初始的line、column、block状态
for(int j = 0; j < board[0].size(); j ++){
if(board[i][j] == '.'){
emptyspaces.push_back({i ,j});
}
else{
int temp = board[i][j] - '0' - 1;
line[i][temp] = column[j][temp] = block[i / 3][j / 3][temp] = true;
}
}
}
dfs(board, 0);
}
};
46. 全排列
难度:中等
题目:
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例:
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
输入:nums = [0,1] 输出:[[0,1],[1,0]]
输入:nums = [1] 输出:[[1]]
提示:
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
解题思路:
- 直接深度优先遍历,走到头就往回走一个,然后继续往下走
- 要注意的是标注数据可用状态
代码:
cppclass Solution {
public:
void dfs(int depth, vector<int>& nums, vector<bool>& status, vector<int>& temp, vector<vector<int> >& res){
if(depth == nums.size()){ // 如果全部遍历,压入res并返回
res.push_back(temp);
return;
}
for(int i = 0; i < nums.size(); i ++){
if(!status[i]){
temp.push_back(nums[i]); // 压入temp
status[i] = true; // 改变状态为不可用
dfs(depth + 1, nums, status, temp, res); // 对下一个位置进行dfs
temp.pop_back(); // 弹出末尾
status[i] = false; // 改变状态为可用
}
}
}
vector<vector<int> > permute(vector<int>& nums) {
int len = nums.size();
vector<vector<int> > res;
vector<int> temp;
vector<bool> status(len, false);
dfs(0, nums, status, temp, res); // 深度,nums数据,status状态数组,temp临时数组,res返回数组
return res;
}
};
47. 全排列II
难度:中等
题目:
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例:
输入:nums = [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1,1]]
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10
解题思路:
- 大体思路和46题是一样的,只是增加了一个去重的判断
- 考虑如何去重
- 同一个位置,相同的元素只能记录一次,记录两次则有重复
- 为了达到这个目的,我们要记录当前位置的弹出数据记录下来
- 如果我们记录所有的弹出数据,需要额外的空间O(n)来保存
- 用时间换空间:对nums数组排序,这样重复数据就会挨着出现,只需要维护一个常数空间就可以记录弹出数据
代码:
cppclass Solution {
public:
void dfs(int depth, vector<int>& nums, vector<bool>& status, vector<int>& temp, vector<vector<int> >& res){
if(depth == nums.size()){ // 如果全部遍历,压入res并返回
res.push_back(temp);
return;
}
int out = 20; // 记录一个数据范围之外的数作为out
for(int i = 0; i < nums.size(); i ++){
if(!status[i] && nums[i] != out){ // 如果当前要压入的数和刚弹出的数相同,则不能压入
temp.push_back(nums[i]); // 压入temp
status[i] = true; // 改变状态为不可用
dfs(depth + 1, nums, status, temp, res);
out = temp.back(); // 取出最后一个数据
temp.pop_back(); // 弹出末尾
status[i] = false; // 改变状态为可用
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
int len = nums.size();
sort(nums.begin(), nums.end());
vector<int> temp;
vector<vector<int>> res;
vector<bool> status(len, false);
dfs(0, nums, status, temp, res); // 深度,nums数据,status状态数组,temp临时数组,res返回数组
return res;
}
};
51. N皇后
难度:困难
题目:
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例:
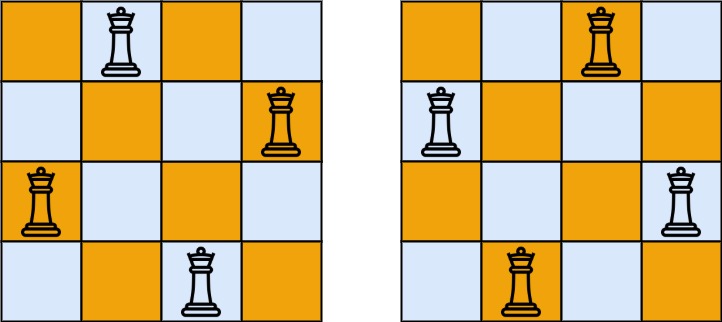
输入:n = 4 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]] 解释:如上图所示,4 皇后问题存在两个不同的解法。
输入:n = 1 输出:[["Q"]]
提示:
1 <= n <= 9
解题思路:
- 皇后不能出现在同一列、同一行、同一对角线
- 那么我们按行进行摆放,就不用考虑同一行的问题,只需要考虑列和对角线
- 对于列:定义
column[i]来存放第i列是否摆放了皇后,初始状态为false - 对于对角线,分为左上到右下和右上到左下
- 左上到右下,定义
left[n-i+j]来存放第i行j列位置对应的对角线是否摆放了皇后,初始状态为false - 右上到左下,定义
right[i+j]来存放第i行j列位置对应的对角线是否摆放了皇后,初始状态为false
- 左上到右下,定义
- 对角线定义规则:
- 不难发现,
n-i+j计算出的左上右下对角线的值都相同 - 同理,
i+j计算出的右上左下对角线的值也都相同
- 不难发现,
- 对于列:定义
- 如果满足了行、列、对角线条件,那么就在当前位置摆放皇后并改变位置状态
- 继续从当前位置出发进行下一行的遍历
- 结束了当前位置的遍历后,恢复位置状态,扫描当前行的下一个位置
代码:
cppclass Solution {
public:
bool column[10];
bool left[20];
bool right[20];
void dfs(int depth, int n, vector<vector<string>>& res, vector<string>& temp){
if(depth == n){ // 满足条件,将temp压入res
res.push_back(temp);
return;
}
for(int i = 0; i < n; i ++){
if(!column[i] && !left[n - (depth - i)] && !right[depth + i]){
column[i] = left[n - depth + i] = right[depth + i] = true; // 改变状态为不可用
temp[depth][i] = 'Q'; // 记录当前位置为 Q
dfs(depth + 1, n, res, temp); // 进入下一行
column[i] = left[n - depth + i] = right[depth + i] = false; // 改变状态为可用
temp[depth][i] = '.'; // 恢复当前位置为 .
}
}
}
vector<vector<string>> solveNQueens(int n) {
vector<vector<string>> res; // 返回值
vector<string> temp(n, string(n, '.')); // 临时存放摆放情况
dfs(0, n, res, temp);
return res;
}
};
52. N皇后II
难度:困难
题目:
n 皇后问题 研究的是如何将 n 个皇后放置在 n × n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。
示例:
输入:n = 4 输出:2 解释:如上图所示,4 皇后问题存在两个不同的解法。
输入:n = 1 输出:1
提示:
1 <= n <= 9
解题思路:
同51题 N皇后的思路,只是把求结果变成了求结果个数
代码:
cppclass Solution {
public:
bool column[10];
bool left[20], right[20];
int res = 0;
void dfs(int depth, int n){
if(depth == n){ // 只需要计数就好
res ++;
return;
}
for(int i = 0; i < n; i ++){
if(!column[i] && !left[n - depth + i] && !right[depth + i]){ // 判断是否可用
column[i] = left[n - depth + i] = right[depth + i] = true; // 改变状态为不可用
dfs(depth + 1, n); // 进入下一行
column[i] = left[n - depth + i] = right[depth + i] = false; // 改变状态为可用
}
}
}
int totalNQueens(int n) {
dfs(0, n);
return res;
}
};
77. 组合
难度:中等
题目:
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例:
输入:n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
输入:n = 1, k = 1 输出:[[1]]
提示:
1 <= n <= 201 <= k <= n
解题思路:
- 前面做的都是全排列问题,要求出相关问题的所有情况
- 这道题是组合问题,要除去重复的情况。因此我们不能沿用前面从0到n的遍历方法
- 如果从0到n遍历,会出现
- 第一个数是0,记录了所有以0开头的情况
- 将0弹出,以1为第一个数,又要记录所有以1开头的情况,必然会重复记录0
- 因此会出现重复情况
- 为了避免重复,我们不能让做过开头的数字再出现在扫描列表里
- 所以不使用for循环,而是用两次递归调用
- 第一次为使用当前数
- 第二次为不使用当前数
- 由此我们达成了组合数的要求
代码:
cppclass Solution {
public:
void dfs(vector<vector<int>>& res, vector<int>& temp, int depth, int k, int n){
if(temp.size() + n - depth + 1 < k){
return;
}
if(temp.size() == k){
res.push_back(temp);
return;
}
// 组合不是排列,所以不能用循环,否则会出现重复的情况
temp.push_back(depth);
dfs(res, temp, depth + 1, k, n);
temp.pop_back();
dfs(res, temp, depth + 1, k, n);
}
vector<vector<int>> combine(int n, int k) {
vector<vector<int>> res;
vector<int> temp;
dfs(res, temp, 1, k, n);
return res;
}
};
78. 子集
难度:中等
题目:
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例:
输入:nums = [1,2,3] 输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
输入:nums = [0] 输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
解题思路:
- 子集问题,属于组合类问题,而且不需要加任何的判断条件,遍历到底就可以了
- 每次传入一个当前位置就好
- 在
dfs的开头将temp压入res,之后再对temp做修改
代码:
cppclass Solution {
public:
vector<vector<int>> res;
vector<int> temp;
void dfs(vector<int>& nums, int position){
res.push_back(temp); // 每次遍历开始前将temp压入res,同时也就压入了一个[]
for(int i = position; i < nums.size(); i ++){ // 组合问题,从当前位置开始遍历
temp.push_back(nums[i]); // 压入temp
dfs(nums, i + 1); // 进入新一轮遍历
temp.pop_back(); // 弹出
}
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return res;
}
};
79. 单词搜索 🌟
难度:中等
题目:
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例:
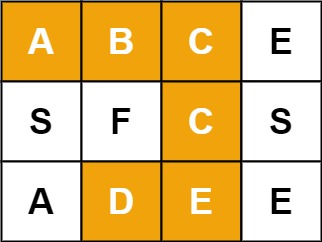
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED" 输出:true
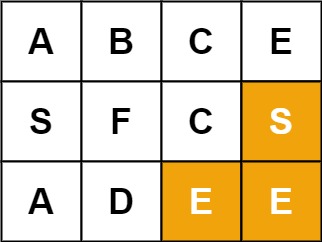
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE" 输出:true

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB" 输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成
**进阶:**你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
解题思路:
刷题太少,回溯相关的题目一下子想不出方法,这个题是完全看了官方题解🤦♂️
首先,要在board中找到和word相匹配的序列,需要将board完全遍历一次,对于每一个字符都应该尝试作为序列的开头去检查。
因此我们需要求出board的行数和列出,然后对board进行遍历,检查每一个字符是否可以作为序列的首字母
如果当前字母满足了作为首字母的条件,那么沿着当前字母继续搜索:
- 规定四个方向,即上下左右
- 对于当前字母,要将四个方向全部检查一次,看是否满足序列下一个字母的需求
- 满足,沿新字母继续搜索四个方向;不满足,换下一个方向
- 重复上述操作至搜索完毕
那么我们可以定义check函数来判断是否可以沿当前字母走下去,重复调用即可
要注意的是:需要定义一个visited数组来保存在当前搜索中,board中字母是否被使用过;除此之外,满足条件,需要将字母标记为true,在进入下一个字母的检查时,要将当前字母的使用情况变为false,以便后续遍历使用
时间复杂度为O(mn * 3^L) (就是DFS)
代码:
cppclass Solution {
public:
vector<pair<int, int>> directions{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
bool dfs(vector<vector<char>>& board, vector<vector<bool>>& visited, int i, int j, string word, int k){
if(k == word.length() - 1){ // 如果全部遍历完成,说明成功
return true;
}
for(const auto& dir: directions){
int newi = i + dir.first, newj = j + dir.second; // 找一个方向
if(newi >= 0 && newi < board.size() && newj >= 0 && newj < board[0].size()){
if(!visited[newi][newj] && board[newi][newj] == word[k + 1]){ // 条件判断
visited[newi][newj] = true; // 改变状态位
bool res = dfs(board, visited, newi, newj, word, k + 1); // 进入新一轮遍历
visited[newi][newj] = false; // 恢复状态位
if(res){
return true;
}
}
}
}
return false;
}
bool exist(vector<vector<char>>& board, string word) {
int m = board.size();
int n = board[0].size();
vector<vector<bool>> visited(m, vector<bool>(n));
for(int i = 0; i < m; ++ i){ // 寻找合适的首字母位置
for(int j = 0; j < n; ++ j){
if(board[i][j] == word[0]){ // 如果当前首字母满足条件,进入新一轮遍历
visited[i][j] = true; // 改变状态位
bool res = dfs(board, visited, i, j, word, 0); // 遍历
visited[i][j] = false; // 恢复状态位
if(res){ // 判断是否成功
return true;
}
}
}
}
return false;
}
};
90. 子集II
难度:中等
题目:
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例:
输入:nums = [1,2,2] 输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
输入:nums = [0] 输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10
解题思路:
在78 子集的基础上,多两步操作
- 多一步排序,即按顺序排列,方便后续求解;
- 再多一步判断当前遍历字母和前一个是否相同以及前一个字母是否在使用中
- 如果相同且前一个字母没有在使用,那么当前字母不能使用,因为所有的只存在一个该字母的子集已经全部被前一个遍历到了
- 反之,当前字母可以使用
代码:
cppclass Solution {
public:
vector<vector<int>> res;
vector<int> temp;
bool status[10];
void dfs(vector<int>& nums, int position){
res.push_back(temp); // 压入空
for(int i = position; i < nums.size(); i ++){
if(i > 0 && nums[i] == nums[i - 1] && !status[i - 1]){
continue;
}
temp.push_back(nums[i]); // 压入temp
status[i] = true; // 改变状态位
dfs(nums, i + 1); // 进入新一轮遍历
status[i] = false; // 恢复状态位
temp.pop_back(); // 弹出
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end()); // 排序
dfs(nums, 0);
return res;
}
};
93. 复原IP地址
难度:中等
题目:
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
- 例如:
"0.1.2.201"和"192.168.1.1"是 有效 IP 地址,但是"0.011.255.245"、"192.168.1.312"和"192.168@1.1"是 无效 IP 地址。
给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 '.' 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
示例:
输入:s = "25525511135" 输出:["255.255.11.135","255.255.111.35"]
输入:s = "0000" 输出:["0.0.0.0"]
输入:s = "101023" 输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
提示:
1 <= s.length <= 20s仅由数字组成`
解题思路:
- 尝试每一个可以插入点的位置,当用该位置做分割时,是否满足合法IP
- 判断IP子串是否合法
- 子串长度为1-3
- 无前导零且不能有非法字符
- 子串小于255
- 对于每一个可以插入点的位置,插入点后,将position+2后进入下一轮遍历
- 退出本轮遍历后删除点,尝试对下一个位置进行插入
代码:
cppclass Solution {
public:
vector<string> res;
bool checknum(string s){
if(s.size() == 0 || s.size() > 3){ // 如果子串长度为0或者大于3,不合法
return false;
}
if(s[0] == '0' && s.size() != 1){ // 如果前导零且长度不为1,不合法
return false;
}
int res = 0;
for(int i = 0; i < s.size(); i ++){
if(s[i] > '9' || s[i] < '0'){ // 如果有非数字,不合法
return false;
}
res = res * 10 + s[i] - '0';
}
if(res > 255){ // 如果子串大于255,不合法
return false;
}
return true;;
}
void dfs(string& s, int depth, int position){ // s,字符串;depth,深度,即已经插入的点数;position,当前要插入的位置
if(depth == 3){ // 当三个点全部被插入后,判断最后一段是否满足要求
if(checknum(s.substr(position))){ // 满足,将s压入res中
res.push_back(s);
}
return;
}
for(int i = position; i < s.size(); i ++){ // 从当前的第一个可插入位置开始遍历
if(checknum(s.substr(position, i + 1 - position))){ // 当发现合法子串
s.insert(s.begin() + i + 1, '.'); // 插入一个点
dfs(s, depth+1, i + 2); // 因为插入了点,所以s的长度加一,position需要加2才能到达下一个可插入位置
s.erase(s.begin() + i + 1);
}
else{ // 当前子串不合法,后面全不合法
break;
}
}
}
vector<string> restoreIpAddresses(string s) {
if(s.size() > 12){ // 不可能为合法IP
return res;
}
dfs(s, 0, 0);
return res;
}
};
126. 单词接龙II 🌟 🤦♂️🤦♂️
难度:困难
题目:
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
- 每对相邻的单词之间仅有单个字母不同。
- 转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。 sk == endWord
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
示例:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] 解释:存在 2 种最短的转换序列: "hit" -> "hot" -> "dot" -> "dog" -> "cog" "hit" -> "hot" -> "lot" -> "log" -> "cog"
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:[] 解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。
提示:
1 <= beginWord.length <= 5endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有单词 互不相同
解题思路:
回溯法太难了🤦♂️又是看了官方题解的一题,而且还看了好久
- 求最短路径,想到广度优先搜索,但题里面没给出图,所以我们需要自己建立一张图来供我们做遍历
- 通过建图,找到了beginword和endword的通路,那么接下来就通过深度优先搜索来找到所有的最短路径
- 注:
- 对于每个单词的每个字母,都需要从
a到z替换一次,看看nextword是否满足条件,即:- 是否在dict中
- 层数是否满足要求
- 对于存在dict中的每个nextword,在使用后都需要删除,防止影响后续搜索
- 对于每个单词的每个字母,都需要从
(这道题的官方题解太差了,从代码质量到题解可读性都差,后面会再学一下回溯和STL相关知识,自己重新做一次)
代码:
cppclass Solution {
public:
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
vector<vector<string>> res;
unordered_set<string> dict = {wordList.begin(), wordList.end()}; // 建立哈希表
if(dict.find(endWord) == dict.end()){ // 如果wordList中没有endword
return res;
}
dict.erase(beginWord); // 在dict中删除beginword,防止后续搜索时影响结果
// 1. 广度优先遍历图
unordered_map<string, int> steps = {{beginWord, 0}}; // 记录是第几层,类似于树状
unordered_map<string, set<string>> from = {{beginWord, {}}}; // 记录一个单词可以从哪些单词扩展得来,或者说可以扩展得到哪些单词
int step = 0; // beginword在第0层
bool found = false; // 记录有无路线可以得到endword
queue<string> q = queue<string>{{beginWord}}; // 建立队列,用于广度优先搜索
int wordlen = beginWord.length(); // 获得单词长度
while(!q.empty()){ // 当前队列不为空,则可以继续搜索;搜索顺序为,获取队头,找到队头可以走到的所有单词并放在队尾
step ++; // 层数++
int size = q.size(); // 获得当前q的长度
for(int i = 0; i < size; ++ i){ // 遍历当前队列的每一个元素,对每个元素进行广度搜索
const string currword = move(q.front()); // std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁或者内存拷贝
string nextword = currword; // 先将nextword定义为currword,然后尝试修改每一个字母得到新单词
q.pop(); // 将队头删除
for(int j = 0; j < wordlen; ++ j){
const char originchar = nextword[j];
for(char c = 'a'; c <= 'z' ; ++ c){ // 尝试替换为所有字母
nextword[j] = c;
if(dict.find(nextword) == dict.end()){ // dict中没有nextword
if(steps[nextword] == step){ // 如果在层数上满足条件,就在from里插入,表明可以从currword到nextword;
// 这里加入这个判断的原因是,nextword可能是被从dict中删除的,而不是一直不存在,如果不写这个判断就会导致被删除单词再次被遍历到后无法根据层数做插入逻辑
from[nextword].insert(currword);
}
continue;
}
dict.erase(nextword); // 从dict中删除nextword,类似于删除beginword一样,防止已遍历过的单词影响后续搜索
q.push(nextword); // 进入队列等待从该单词进行广度搜索
from[nextword].insert(currword); // 在from里插入,表明可以从currword到nextword
steps[nextword] = step; // 记录nextword的层数
if(nextword == endWord){
found = true;
}
}
nextword[j] = originchar;
}
}
if(found){ // 找到了变成endword的路,退出当前循环,后面的只会更长,没有意义,不需要遍历了
break;
}
}
// 2. 深度优先遍历图
if(found){ // 如果有解,从endword向beginword逐步恢复,
vector<string> Path = {endWord};
dfs(res, endWord, from, Path); // res:返回值; endword:出发点; from:单词和单词之间的连通情况; Path:整体恢复路线
}
return res;
}
void dfs(vector<vector<string>> &res, const string &Node, unordered_map<string, set<string>> &from, vector<string> &path){
if(from[Node].empty()){ // 如果from[Node]为空,表示已经恢复到了beginword,因为在初始化时,beginword对应的value为空
res.push_back({path.rbegin(), path.rend()}); // std::rbegin()的返回值是std::end(),反转了一下begin()
return;
}
for(const string &Parent: from[Node]){ // 对每一个可以到达Node的单词做dfs,尝试恢复到beginword
path.push_back(Parent); // 压入当前结点
dfs(res, Parent, from, path); // 对当前结点做dfs尝试恢复到beginword
path.pop_back(); // 弹出Parent,状态恢复
}
}
};
131. 分割回文串
难度:中等
题目:
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例:
输入:s = "aab" 输出:[["a","a","b"],["aa","b"]]
输入:s = "a" 输出:[["a"]]
提示:
1 <= s.length <= 16s仅由小写英文字母组成
解题思路:
- 思路同复原IP,复原IP是分割字符串后判断是否满足合法IP规则;回文串是分割字符串后判断是否满足回文
- 相比IP,回文串的dfs函数少了参数depth,因为不限制回文子串的个数,所以退出条件变为position等于字符串长度,即本轮遍历已经全部分割
- 因为没有插入的操作,所以position+1即可
- 如果当前分割位置之前子串满足回文,就将子串压入并从当前位置开始进入下一轮分割
- 退出该轮分割后,将子串弹出,对下一个位置继续进行扫描
代码:
cppclass Solution {
public:
vector<vector<string>> res;
vector<string> temp;
bool checkstr(string s){ // 检查子串是否满足回文条件
int left = 0, right = s.size() - 1;
while(left <= right){
if(s[left] == s[right]){
left ++;
right --;
}
else{ // 如果不回文,返回false
return false;
}
}
return true;
}
void dfs(string s, int position){ // s为所给字符串,position为当前开始分割的子串首字母所在位置
if(position == s.size()){ // 如果当前要分割的子串首字母位置已经为s.size(),说明已经分割完毕
res.push_back(temp); // 将temp压入res
}
for(int i = position; i < s.size(); i ++){
if(checkstr(s.substr(position, i + 1 - position))){ // 如果满足回文
temp.push_back(s.substr(position, i + 1 - position)); // 压入temp
dfs(s, i + 1); // 进入下一轮遍历,position移动到回文子串的下一位,即i+1
temp.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
if(s.size() == 1){
temp.push_back(s);
res.push_back(temp);
return res;
}
dfs(s, 0);
return res;
}
};
211. 添加与搜索单词 - 数据结构设计
难度:中等
题目:
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类 WordDictionary :
WordDictionary()初始化词典对象void addWord(word)将word添加到数据结构中,之后可以对它进行匹配bool search(word)如果数据结构中存在字符串与word匹配,则返回true;否则,返回false。word中可能包含一些'.',每个.都可以表示任何一个字母。
示例:
输入: ["WordDictionary","addWord","addWord","addWord","search","search","search","search"] [[],["bad"],["dad"],["mad"],["pad"],["bad"],[".ad"],["b.."]] 输出: [null,null,null,null,false,true,true,true] 解释: WordDictionary wordDictionary = new WordDictionary(); wordDictionary.addWord("bad"); wordDictionary.addWord("dad"); wordDictionary.addWord("mad"); wordDictionary.search("pad"); // 返回 False wordDictionary.search("bad"); // 返回 True wordDictionary.search(".ad"); // 返回 True wordDictionary.search("b.."); // 返回 True
提示:
1 <= word.length <= 25addWord中的word由小写英文字母组成search中的word由 '.' 或小写英文字母组成- 最多调用
104次addWord和search
解题思路:
-
用二维数组来实现前缀树
tire[N][26]表示前缀树cnt[N]表示是否有以该索引代表的字母结尾的单词,换成int型就可以表示为以该字母结尾的单词个数idx代表索引,从0开始,0既是根节点,又是空节点
-
将每一个字母对应为相应的数字,即
int temp = word[i] - 'a'; -
对于插入操作
- 检查对于当前的父节点,子节点
word[i]是否已存在;- 存在,就沿着路线走;
- 不存在,就创造一个子节点,
tire[p][temp] = ++ idx;并沿着走
- 最后将
cnt[p]标记为true,如果要记录个数就对cnt[p]++
- 检查对于当前的父节点,子节点
-
对于搜索操作
-
检查对于当前的父节点,子节点
word[i]是否已存在;-
存在,就沿着路线走;
-
不存在,返回false
-
-
最后判断
cnt[depth]是否为true即可,即判断有无以最后一个字母结尾的单词
-
代码:
cppclass WordDictionary {
public:
int tire[250000][26] = {0}; // 初始化tire为0
bool cnt[250000]; // 记录字符串存在情况
int idx = 0; // 指针
WordDictionary() {
}
void addWord(string word) {
int p = 0;
for(int i = 0; i < word.size(); i ++){ // 将word的每一个字母转为数字存入tire
int temp = word[i] - 'a';
if(!tire[p][temp]){ // 如果当前位置没有存字母
tire[p][temp] = ++ idx; // 就标记为++idx
}
p = tire[p][temp]; // 指针移动到当前字母所代表的位置
}
cnt[p] = true; // 将最后一个字母所在位置的标记设为true,代表有以该字母结尾的单词
}
bool search(string word) {
return dfs(word, 0, 0);
}
bool dfs(string word, int position, int depth){ // word,要搜索的单词;position,当前比较到的位置;depth,父节点,也可以理解为在前缀树上的深度
if(position == word.size()){ // 如果对word遍历结束,判断是否存在以最后一个字母结尾的单词
return cnt[depth];
}
if(word[position] != '.'){ // 如果当前字符是普通字母
int temp = word[position] - 'a'; // 计算对应的下标并查看是否存在
if(!tire[depth][temp]){ // 不存在,返回false
return false;
}
else{ // 存在,移动指针到tire[depth][temp],并对下一个字母进行检查
return dfs(word, position + 1, tire[depth][temp]);
}
}
else{ // 如果是 '.'
int flag = false; // 先设一个flag为false
for(int j = 0; j < 26; j ++){ // 因为'.'可以表示所有字母,就遍历26个字母
if(tire[depth][j]){ // 如果当前字母存在,就从该字母进入下一轮遍历;否则换下一个字母判断
flag = flag || dfs(word, position + 1, tire[depth][j]); // 做或运算,有一个成立即可
}
if(flag){ // 剪枝,不用判断后面了
return true;
}
}
return flag;
}
return false; // 如果没有满足cnt[depth]=true,就只能返回false了
}
};
/**
* Your WordDictionary object will be instantiated and called as such:
* WordDictionary* obj = new WordDictionary();
* obj->addWord(word);
* bool param_2 = obj->search(word);
*/
212. 单词搜索II 🌟 🤦♂️🤦♂️
难度:困难
题目:
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例:
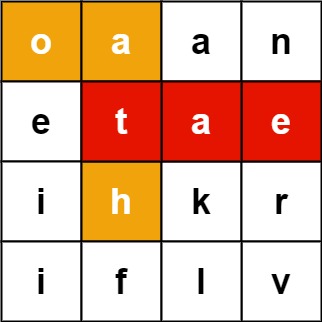
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]
输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同
解题思路:
-
很显然,当我企图用单词搜索的方法加一个遍历来做这道题,它狠狠的超时了😫
-
继续借鉴微扰理论大神的思路
-
做这道题需要对时间复杂度做一个精打细算,要不然C++可能会勉强过,其他的都得WA
-
考虑当我们找到一个单词的结尾时,有可能继续往下走还有另一个单词,而不是从头再来
-
寻找单词首字母合适位置时
- 如果用单词首字母去找对应的
board[i][j],需要words.length * n * m - 如果我们先建立前缀树,只需要拿到
board[i][j],就可以直接判断出有无首字母,是nm
- 如果用单词首字母去找对应的
-
寻找后续的字母位置
- 从定好的方向中选一个出来走,判断一下状态,不走回头路,和
79.单词搜索思路一样 - 当遇到一个单词末尾的时候,继续选方向往下走,因为有可能有其他单词的前缀是当前单词,例如
abcd和abcde
- 从定好的方向中选一个出来走,判断一下状态,不走回头路,和
-
去重
- 可能在
board中存在不止一条路可以找到一个单词,这样就会产生重复情况,例如示例二 - 有两种去重办法
- 第一种是在前缀树中加入一个
bool值来记录当前单词是否已被压入 - 第二种是采用
unordered_set来存储word,之后从中取出压入res,底层实现为hash,因此不会出现重复元素
- 第一种是在前缀树中加入一个
- 可能在
-
前缀树的建立
- 可以自定义数据结构
TrieNode - 也可以采用二维数组来构成前缀树,见算法模板总结的前缀树部分
- 可以自定义数据结构
代码:
cppstruct TrieNode{ // 定义前缀树的数据结构
vector<TrieNode*> children;
bool isWordEnd;
bool isAdd;
TrieNode(){
children = vector<TrieNode*>(26, NULL);
isWordEnd = false;
isadd = false;
}
};
class Solution {
public:
vector<pair<int, int>> directions{{0, 1}, {0, -1}, {1, 0}, {-1, 0}}; // 定义方向
vector<string> res; // 返回值
void dfs(vector<vector<char>>& board, string& word, int i, int j, TrieNode* root){
char nowchar = board[i][j]; // 当前位置的字符
int nowindex = nowchar - 'a'; // 得到当前字符的索引
if(root->children[nowindex] == NULL){ // 如果该索引对应的位置为NULL,说明没有这个单词,返回
return;
}
board[i][j] = '0'; // 将board[i][j]标记为'0',代表正在使用
word += nowchar; // 记录当前遍历到的合法单词子串
if(root->children[nowindex]->isWordEnd && !root->children[nowindex]->isAdd){ // 如果当前位置是单词的结尾并且该单词没有被压入到res中,将其压入
root->children[nowindex]->isAdd = true; // 修改该单词的压入情况,去重
res.push_back(word);
}
for(auto& dir:directions){ // 遍历四个方向
int newi = i + dir.first, newj = j + dir.second;
if(newi >= 0 && newi < board.size() && newj >= 0 && newj < board[0].size()){ // 该方向为合法方向
if(board[newi][newj] != '0'){ // 该位置在当前单词的搜索中没有被使用过
dfs(board, word, newi, newj, root->children[nowindex]); // 进入新一轮遍历
}
}
}
board[i][j] = nowchar; // 恢复当前位置状态
word.pop_back(); // 弹出
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
TrieNode* root = new TrieNode(); // 新建前缀树的根结点
for(auto word: words){ // 建立前缀树
TrieNode* p = root;
for(auto c:word){
int index = c - 'a';
if(p->children[index] == NULL){
p->children[index] = new TrieNode();
}
p = p->children[index];
}
p->isWordEnd = true;
}
string word = ""; // 定义搜索到的合法单词子串
for(int i = 0; i < board.size(); i ++){ // 遍历board的每一个位置作为单词的首字母位置
for(int j = 0; j < board[0].size(); j ++){
dfs(board, word, i, j, root); // 进入遍历
}
}
return res;
}
};
216. 组合总数III
难度:中等
题目:
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例:
输入: k = 3, n = 7 输出: [[1,2,4]] 解释: 1 + 2 + 4 = 7 没有其他符合的组合了。
输入: k = 3, n = 9 输出: [[1,2,6], [1,3,5], [2,3,4]] 解释: 1 + 2 + 6 = 9 1 + 3 + 5 = 9 2 + 3 + 4 = 9 没有其他符合的组合了。
输入: k = 4, n = 1 输出: [] 解释: 不存在有效的组合。 在[1,9]范围内使用4个不同的数字,我们可以得到的最小和是1+2+3+4 = 10,因为10 > 1,没有有效的组合。
提示:
2 <= k <= 91 <= n <= 60
解题思路:
- 观察题目可知这是一道组合题,不能包含相同的组合
- 按照组合题的做法,我们向
dfs函数中传入一个position参数代表当前遍历到的位置,避免重复遍历之前的数据 - 考虑
dfs的结束条件:使用了k个数且和为n,将temp压入res中并返回 dfs的遍历方式- 从
position开始遍历,当找到了符合要求的值,压入temp,并从下一个位置进行新一轮遍历 - 结束本次遍历后,将该值从
temp中弹出, - 继续进行
for循环
- 从
代码:
cppclass Solution {
public:
vector<vector<int>> res;
vector<int> temp;
void dfs(int k, int n, int position, int number, int sum){
if(number == k){ // 如果已经使用了k个数,判断和是否为n
if(sum == n){ // 为n,将temp压入res
res.push_back(temp);
}
return;
}
for(int i = position; i <= 9; i ++){
if(sum + i <= n && number + 1 <= k){ // 如果数字之和、个数均在范围内,从该数字的下一位进入下一轮循环
temp.push_back(i); // 压入
dfs(k, n, i + 1, number + 1, sum + i);
temp.pop_back(); // 弹出
}
else{ // 剪枝
break;
}
}
}
vector<vector<int>> combinationSum3(int k, int n) {
dfs(k, n, 1, 0, 0);
return res;
}
};
306. 累加数 🌟
难度:中等
题目:
累加数 是一个字符串,组成它的数字可以形成累加序列。
一个有效的 累加序列 必须 至少 包含 3 个数。除了最开始的两个数以外,序列中的每个后续数字必须是它之前两个数字之和。
给你一个只包含数字 '0'-'9' 的字符串,编写一个算法来判断给定输入是否是 累加数 。如果是,返回 true ;否则,返回 false 。
**说明:**累加序列里的数,除数字 0 之外,不会 以 0 开头,所以不会出现 1, 2, 03 或者 1, 02, 3 的情况。
示例:
输入:"112358" 输出:true 解释:累加序列为: 1, 1, 2, 3, 5, 8 。1 + 1 = 2, 1 + 2 = 3, 2 + 3 = 5, 3 + 5 = 8
输入:"199100199" 输出:true 解释:累加序列为: 1, 99, 100, 199。1 + 99 = 100, 99 + 100 = 199
提示:
1 <= num.length <= 35num仅由数字(0-9)组成
**进阶:**你计划如何处理由过大的整数输入导致的溢出?
解题思路:
- 本题解法来自 微扰理论大神
- 观察数据范围可知,
num的长度最大为35,可能会导致first和second发生溢出,所以采用大数加法,或者叫高精度加法 - 因为是斐波那契数列的变式,因此我们只需要确定第一个数和第二个数的位置即可,后续的直接和两数之和对比
- 相等,进入新一轮对比
- 不相等,返回false
- 微扰理论大神 用字符串比较代替了数字比较
- 一方面避免了大数溢出的情况
- 另一方面省去了字符串和整型的转换,直接使用字符串的每一位比较,还可以用长度来做剪枝判断
- 几点细节
- 传入first、second、sum的首地址
- 判断first、second是否为非法数据,即是否为前导零且长度不为1
- 判断两数之和的长度和剩余长度的大小关系
- 如果两数之和更大,那么sum一定小于first + second
- 如果在逐一对比无误,且两数之和的长度与剩余长度相同,说明已经全部对比过,满足累加数条件
- 如果两数之和的长度小于剩余长度,说明还未遍历过整个字符串,进入新一轮遍历
代码:
cppclass Solution {
public:
string addNum(string &s1, string &s2){ // 大数加法
int n1 = s1.size() - 1;
int n2 = s2.size() - 1;
int carry = 0;
string ans;
while(n1 >= 0 || n2 >= 0 || carry > 0){
int t1 = n1 >= 0 ? s1[n1--] - '0' : 0;
int t2 = n2 >= 0 ? s2[n2--] - '0' : 0;
ans += (t1 + t2 + carry) % 10 + '0';
carry = (t1 + t2 + carry) / 10;
}
reverse(ans.begin(), ans.end());
return ans;
}
bool check(string num, int first, int second, int sum){ // 第一个数、第二个数、两数之和的开头位置
if(num[first] == '0' && second - first > 1){ // 如果为非法数字,返回false
return false;
}
if(num[second] == '0' && sum - second > 1){
return false;
}
string firststr = num.substr(first, second - first);
string secondstr = num.substr(second, sum - second);
string tempsum = addNum(firststr, secondstr); // 大数加法,返回字符串
if(tempsum.size() > num.size() - sum){ // 如果两数之和的字符串长度大于剩余长度,则一定不能匹配
return false;
}
for(int i = 0; i < tempsum.size(); i ++){
if(tempsum[i] != num[sum + i]){ // 如果出现字符不匹配,返回false
return false;
}
}
if(tempsum.size() == num.size() - sum){ // 如果全部匹配且遍历完整个num,返回true
return true;
}
return check(num, second, sum, sum + tempsum.size()); // 递归调用check
}
bool isAdditiveNumber(string num) {
int len = num.size();
for(int second = 1; second < len; second ++){
for(int sum = second + 1; sum < len; sum ++){
if(check(num, 0, second, sum)){
return true;
}
}
}
return false;
}
};
526. 优美的排列
难度:中等
题目:
假设有从 1 到 n 的 n 个整数。用这些整数构造一个数组 perm(下标从 1 开始),只要满足下述条件 之一 ,该数组就是一个 优美的排列 :
perm[i]能够被i整除i能够被perm[i]整除
给你一个整数 n ,返回可以构造的 优美排列 的 数量 。
示例:
输入:n = 2 输出:2 解释: 第 1 个优美的排列是 [1,2]: - perm[1] = 1 能被 i = 1 整除 - perm[2] = 2 能被 i = 2 整除 第 2 个优美的排列是 [2,1]: - perm[1] = 2 能被 i = 1 整除 - i = 2 能被 perm[2] = 1 整除
输入:n = 1 输出:1
提示:
1 <= n <= 15
解题思路:
- 观察发现这是一道排列题型,根据判断条件的不同,数据可以颠倒出现,例如
[1,2]和[2,1] - 考虑
dfs结束条件:已经使用了n个数,就可以让res++了,因为只有符合条件的才会进入新一轮遍历 - 对于排列题型,在
dfs的遍历中要从头开始,本题要求下标从1开始,那我们就让i从1开始遍历 dfs的遍历方式- 判断是否满足条件,满足就改变当前位置的状态并从下一个位置进入新一轮遍历
- 退出遍历后,再次改变当前状态位置
- 继续
for循环
代码:
cppclass Solution {
public:
int res = 0;
bool status[16];
void dfs(int n, int number){
if(number == n + 1){ // 数组填满,将res++
res++;
return;
}
for(int i = 1; i <= n; i ++){ // 因为是排列问题,所以从头开始遍历
if(!status[i] && (i % number == 0 || number % i == 0)){ // 如果满足条件
status[i] = true; // 改变位置状态
dfs(n, number + 1); // 从下一个位置开始新一轮遍历
status[i] = false; // 改变位置状态
}
}
}
int countArrangement(int n) {
dfs(n, 1);
return res;
}
};
842. 将数组拆分成斐波那契序列
难度:中等
题目:
给定一个数字字符串 num,比如 "123456579",我们可以将它分成「斐波那契式」的序列[123, 456, 579]。
形式上,斐波那契式 序列是一个非负整数列表 f,且满足:
0 <= f[i] < 231,(也就是说,每个整数都符合 32 位 有符号整数类型)f.length >= 3- 对于所有的
0 <= i < f.length - 2,都有f[i] + f[i + 1] = f[i + 2]
另外,请注意,将字符串拆分成小块时,每个块的数字一定不要以零开头,除非这个块是数字 0 本身。
返回从 num 拆分出来的任意一组斐波那契式的序列块,如果不能拆分则返回 []。
示例:
输入:num = "1101111" 输出:[11,0,11,11] 解释:输出[110,1,111]也可以。
输入: num = "112358130" 输出: [] 解释: 无法拆分。
输入:"0123" 输出:[] 解释:每个块的数字不能以零开头,因此 "01","2","3" 不是有效答案。
提示:
1 <= num.length <= 200num中只含有数字
解题思路:
- 这道题和累加数类似,思路相同,作为斐波那契序列类型题,只需要判断前两个数的位置,就可以验证整个序列
- 因此我们还是去遍历
second和sum的开始位置,加一个second <= 11和sum <= second + 11来剪枝,因为条件中说明每块的数字在int范围内 - 这道题写的稍微复杂了一点,因为想要巩固一下累加数学到的大数加法的知识
- 简化版
- 去掉大数加法部分,保留
string转long long即可 - 因为每个数都限定在了
int内,所以大数加法没必要
- 去掉大数加法部分,保留
代码:
cppclass Solution {
public:
vector<int> res;
bool status;
long long getNum(string num){ // string转longlong
int len = num.size();
long long resnum = 0;
for(int i = 0; i < len; i ++){
resnum = resnum * 10 + num[i] - '0';
if(resnum > INT_MAX) return -1; // 如果超出int的范围,返回-1
}
return resnum;
}
string addNum(string a, string b){ // 大数加法
int n1 = a.size()-1;
int n2 = b.size()-1;
int carry = 0;
string ans;
while(n1>=0||n2>=0||carry>0){
int t1=n1>=0?a[n1--]-'0':0;
int t2=n2>=0?b[n2--]-'0':0;
ans+=(t1+t2+carry)%10+'0';
carry=(t1+t2+carry)/10;
}
reverse(ans.begin(),ans.end());
return ans;
}
void dfs(string num, int first, int second, int sum){ // num,字符串;first,second,sum,第一个数、第二个、和的首地址
if(sum == num.size()){ // 结束条件,和的首地址为num的结尾
status = true;
return;
}
if(num[first] == '0' && second - first > 1) return; // 判断是否为非法字符
if(num[second] == '0' && sum - second > 1) return;
string firststr = num.substr(first, second - first);
string secondstr = num.substr(second, sum - second);
string tempsum = addNum(firststr, secondstr);
long long temp = getNum(tempsum);
if(temp == -1) return; // 如果temp超出int范围,结束遍历
if(tempsum.size() > num.size() - sum) return; // 如果两数之和的长度大于剩余长度,结束遍历
for(int i = 0; i < tempsum.size(); i ++){ // 逐位比较
if(tempsum[i] != num[sum + i]) return; // 如果有不同的位,结束遍历
}
res.push_back(temp); // 当前和满足斐波那契序列,压入res
dfs(num, second, sum, sum + tempsum.size()); // 进入下一轮遍历
}
vector<int> splitIntoFibonacci(string num) {
int len = num.size(); // 记录长度
for(int second = 1; second < len && second <= 11; second++){ // 第一个数的首地址一定是0,不用管,只需要改变第二个数的首地址即可,11是因为要满足int范围,提前做一下剪枝
for(int sum = second + 1; sum < len && sum <= second + 11; sum ++){
long long firstnum = getNum(num.substr(0, second));
long long secondnum = getNum(num.substr(second, sum - second));
if(firstnum == -1 || secondnum == -1){ // 判断是否在int范围内
break;
}
res.push_back(firstnum); // 将first和second压入res
res.push_back(secondnum);
dfs(num, 0, second, sum); // 进入遍历
if(status){ // 如果在遍历结束后,存在一组满足条件
return res; // 返回res
}
res.clear(); // 如果上一组不满足条件,清空res,改变second和sum的首地址进行新的遍历
}
}
return res;
}
};
1079. 活字印刷
难度:中等
题目:
你有一套活字字模 tiles,其中每个字模上都刻有一个字母 tiles[i]。返回你可以印出的非空字母序列的数目。
**注意:**本题中,每个活字字模只能使用一次。
示例:
输入:"AAB" 输出:8 解释:可能的序列为 "A", "B", "AA", "AB", "BA", "AAB", "ABA", "BAA"。
输入:"AAABBC" 输出:188
输入:"V" 输出:1
提示:
1 <= tiles.length <= 7tiles由大写英文字母组成
解题思路:
- 和子集是类型题,就是要求出所有的不重复非空子集,对子集进行一个排列
- 注意点
- 不重复,因此我们需要提前对titles进行排序,这样可以做到跳过重复字母
- 排列,因此每次遍历时从头开始
- 如果当前字母和前一个字母相等,且前一个字母没有被使用,则当前字母也不能被使用。因为所有的情况已经被前一个字母遍历到了
代码:
cppclass Solution {
public:
int res = 0;
bool status[7]; // 定义状态数组,记录可用情况
void dfs(string tiles){
for(int i = 0; i < tiles.size(); i ++){ // 因为是排列问题,从头开始遍历
if(i > 0 && tiles[i] == tiles[i - 1] && status[i - 1] == false){ // 如果当前字母和前一个字母相同且前一个字母为可用状态,则当前字母不能使用;因为前一个字母已经将单个该字母的情况全部列出
continue;
}
if(!status[i]){ // 如果该字母可用
status[i] = true; // 改变状态
res++;
dfs(tiles); // 进入新一轮遍历
status[i] = false; // 恢复状态
}
}
}
int numTilePossibilities(string tiles) {
sort(tiles.begin(), tiles.end()); // 对titles进行排序,让字母有序,方便后续遍历去重
dfs(tiles); // 进入遍历
return res; // 返回res
}
};
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!