目录
Caron M, Touvron H, Misra I, et al. Emerging properties in self-supervised vision transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 9650-9660. Facebook AI Research PDF
1. 摘要
提出了一个假设,即使用自监督学习来预训练ViT可能会带来比有监督学习更好的效果和特性:
- 自监督ViT特征明确地包含了图像的语义分割信息,这在有监督的ViT或convnets中并没有明显地出现。
- 这些特征在k-NN上效果良好,在ImageNet上达到了78.3%的top-1准确率。
- 该研究还强调了动量编码器、多裁剪训练和使用小块的重要性。
将上述发现,整合为一个简单的自监督方法,称为DINO。它可以被解释为一种无标签的自蒸馏形式,它通过直接预测教师网络的输出来简化自监督训练,使用标准交叉熵损。通过在ViT-Base上达到80.1%的ImageNet线性评估准确率,展示了DINO和ViT之间的协同作用。

这是一个无监督训练的8×8块视觉变换器的自注意力。该模型自动学习了特定于类别的特征,从而引导的无监督对象分割。
2. 方法
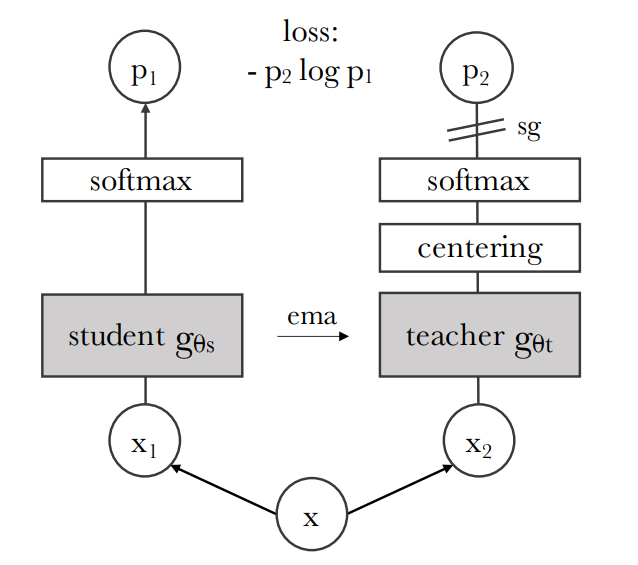
DINO的无标签自蒸馏方法:以一个输入图像为例,生成两个不同的随机视图(x1和x2),分别传递给学生和教师网络。两个网络有相同的结构,但参数不同。教师网络的输出被中心化,减去一个在批次上计算的均值。每个网络输出一个K维特征,用一个温度softmax函数在特征维度上进行归一化得到P。
训练学生网络匹配给定教师网络的输出,分别由和参数化。给定一个输入图像,两个网络在维上输出概率分布,用和表示。概率是通过用软极大函数将网络的输出归一化得到的。是温度参数,控制输出分布的锐度。
然后用交叉熵损失来匹配两个网络输出的概率分布(衡量相似性)。
教师网络上有一个停止梯度(sg)操作符,只通过学生网络传播梯度。教师网络的参数用学生网络参数的指数移动平均(ema)来更新。
温度softmax函数是一种激活函数,它可以将一组实数转换为一个概率分布。它的输出是一个与输入相同维度的向量,每个元素的范围是0到1,而且所有元素的和等于1。温度softmax函数引入了一个温度参数τ,用来控制输出概率分布的“软度”或“尖锐度”。温度参数可以影响函数输出的随机性或多样性。数学上,温度softmax函数可以定义为:
其中是输入向量的第个元素,是输入向量的维度,是温度参数。
温度softmax函数在自然语言处理中有很多应用,例如文本生成、语言模型等。它可以帮助模型避免过于自信或重复的输出,增加输出的随机性或多样性。例如,ChatGPT(gpt-3.5-turbo模型)就使用了温度softmax函数来控制生成文本的随机性。
知识蒸馏(Knowledge Distillation)是一种机器学习中的模型压缩方法。它的目的是将一个大型模型(例如深度神经网络或多个模型的集成)中的知识转移给一个更小的模型。虽然大型模型比小型模型具有更高的知识容量,但这种容量可能并未被充分利用。大型模型的评估可能同样耗费计算资源,即使它只利用了很少的知识容量。知识蒸馏可以在不损失有效性的情况下将知识从大型模型转移到小型模型中。由于小型模型评估成本较低,它们可以部署在计算能力较弱的硬件(如移动设备)上。
知识蒸馏已经在机器学习的多个应用领域成功应用,如物体检测、声学模型和自然语言处理等。
避免网络崩溃
自监督的方法,避免崩溃的方法包括:对比损失、聚类约束、预测器或批处理归一化
该论文通过对动量教师网络输出进行居中和锐化来避免模型崩溃。
3. 实验

主要结果:在ImageNet上进行了标准的自监督基准测试,比较了DINO与其他自监督方法在线性分类和k-NN分类上的表现。结果显示,DINO在ViT上取得了最好的结果,达到了80.1%的线性分类准确率和77.4%的k-NN分类准确率。此外,还评估了DINO特征在图像检索、复制检测、视频实例分割等任务上的性能和性质,发现DINO特征具有良好的可迁移性和场景理解能力。
消融研究:通过实验探讨了DINO中不同组件对ViT预训练的影响,包括动量编码器、多裁剪训练、交叉熵损失、预测器等。结果表明,动量编码器、多裁剪训练和交叉熵损失是提高ViT特征质量的重要因素,而预测器则对DINO没有明显影响。此外,还研究了不同输入块大小对ViT特征性能和运行时间的影响,发现减小块大小可以显著提高性能,但也会降低吞吐量。
该文章证明了使用自监督学习预训练标准的ViT模型的潜力,达到了与最好的convnet相当的性能;还提出了两个可以在未来应用中利用的特性:k-NN分类的特征质量有利于图像检索;而特征中包含的场景布局信息也有利于弱监督图像分割。
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!