目录
Cao Y, Hou T, Wang Y, et al. Ariadne: A reinforcement learning approach using attention-based deep networks for exploration[J]. arXiv preprint arXiv:2301.11575, 2023. PDF 新加坡国立大学
1. 摘要
虽然最先进的探索规划者是基于前沿和采样的,受深度强化学习(DRL)最近发展的鼓励,作者提出了ARiADNE,一种基于注意力的神经方法,以获得实时的、非短视的路径规划。
通过对传统自主探索算法的分析,将传统算法的短视性问题划分为两个层次:
- 第一层是空间非短视问题,要求规划者对当前的局部地图进行推理,以平衡探索-利用的权衡
- 第二层是时间非短视问题,要求规划者估计当前决策的未来影响(例如,预测可能来自给定路径规划决策的部分地图的变化)
从两层分别入手,解决短视问题:
- 使用一个策略网络,让代理有效地对空间非短视决策进行排序,而不需要优化长路径。
- 使用一个Critic网络隐式地为机器人提供了估计通过学习状态作用值可能发现的潜在区域的能力,这进一步有助于做出有利于长期效率的决策,从而解决时间上的短视问题。
2. 方法
2.1 将探索作为RL问题
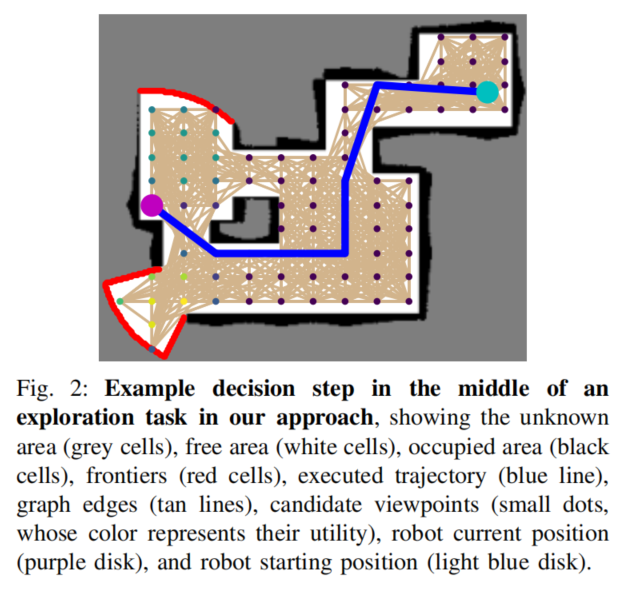
序列决策问题
由于自由区域是根据机器人的运动来更新的,因此自主探索的在线规划本质上是一个顺序决策问题。为了找到视点之间的无碰撞路径,通过一条直线将每个视点与其k个最近邻连接起来,并去除与被占据或未知区域发生碰撞的边缘,由此建立一个无碰撞图。
得到无碰撞图后,让机器人选择其当前位置中的一个相邻节点作为下一个视点。由于该决定将在到达最后一个选择的视点时做出,因此该轨迹是一系列的路径点。
观察
对可见边界进行定义,节点到可见边界的距离小于传感器范围
动作
在每个决策步骤t,给定代理的观察ot,基于注意力的神经网络输出一个随机策略,从所有相邻节点中选择一个节点作为下一个视点。沿直线走到该点,并在途中更新无碰撞地图。
奖励
为了鼓励有效的探索,在完成每一个动作后,机器人会得到由三部分组成的奖励。分别为:可观察到新视点的数量、和之前视点的距离(为负)、探索完成奖励
2.2 策略网络
我们首先依赖于编码器从当前的部分映射中提取显著的特征,特别是通过学习相关的增广图中节点之间的依赖关系。根据这些特征以及当前机器人的位置,解码器在邻近的节点上输出策略,这可以用来决定下一步访问哪个节点。
注意层
使用注意层作为模型中的基本构建块。这种注意层的输入由一个查询向量hq和一个键-值向量h k,v组成。这一层的输出,h 0i,是值向量的加权和,其中的权重取决于键和查询之间的相似性。更新后的特性然后通过一个排在注意层之后的前馈子层传递。
编码器
应用一个边缘掩码允许每个节点只访问其相邻节点的特征,尽管各节点的注意只限于每层的相邻节点,但各节点仍然可以通过这种堆叠的注意结构多次聚合节点特征来获得非相邻节点的特征。最终这些更新的节点特征ˆh ni都包含了v 0i与其他节点的依赖关系。
解码器
使用解码器输出一个基于增强节点特征ˆh和当前机器人位置ψt的策略。
2.3 Critic网络
使用SAC算法来训练策略网络,其中一个Critic网络被训练来预测状态-动作值。
通过Critic网络,能够预测后续的探索奖励。
3. 实验
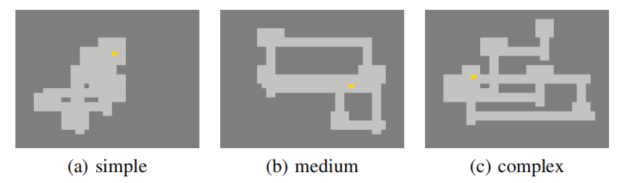
数据集:三种难度类型
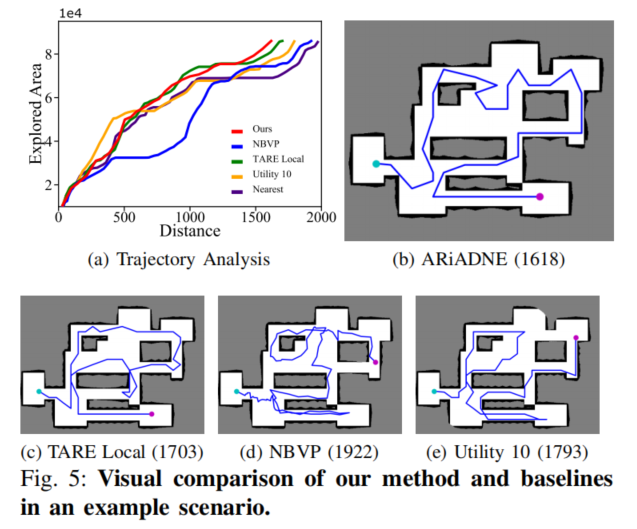
对比方法:Nearest、Utility 1、Utility 10、Utility 25、NBVP、TARE、CNN
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!