目录
Yang, Daniel, et al. "Robotic grasping through combined image-based grasp proposal and 3d reconstruction." 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021. 麻省理工 PDF
1. 摘要
提出了一种新的机器人抓取规划方法,同时使用学习的抓取建议网络和学习的三维形状重建网络。
我们的系统从目标对象的单个RGB-D图像中生成6-DOF的抓取,该图像作为两个网络的输入提供。通过利用几何重建对抓取建议网络产生的候选抓取进行细化,我们的系统能够准确地抓取已知和未知的物体,即使在输入图像上的抓取位置不可见。

流程:提供一个带有分割掩模的RGB-D图像作为输入,这两个神经网络分别产生一个6-DOF的抓取姿态和一个目标的三维点云重建。通过将抓取姿态投影到点云中最近的点上,得到最终的输出抓取。
成功抓取的判定:给定一个来自相机的单一的、分割的RGB-D图像,让机器人抓住和拾起物体。如果在机器人运动结束时,物体被完全从桌子上抬起,被握把牢牢抓住,并且没有被抓握损坏或变形,则被认为是成功的。
2. 方法
2.1 抓取建议网络
使用GPNet架构,输入带有掩码的RGB-D图像,输出为相对于相机的估计抓握姿态
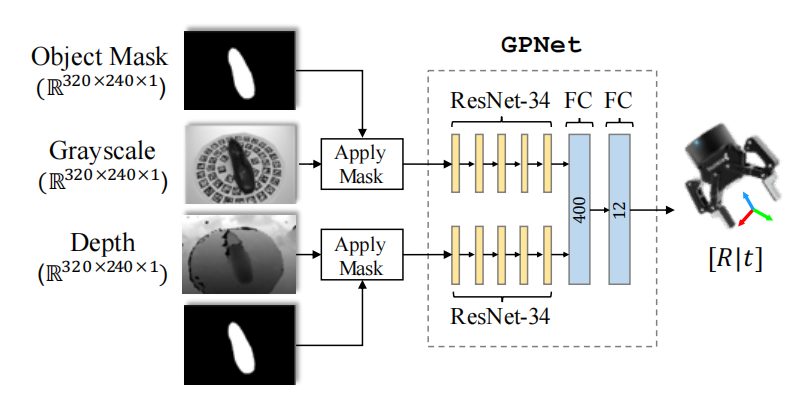
在训练抓取建议网络时,使用基于物理的抓取模拟器GraspIt为每个对象生成Ground truth。
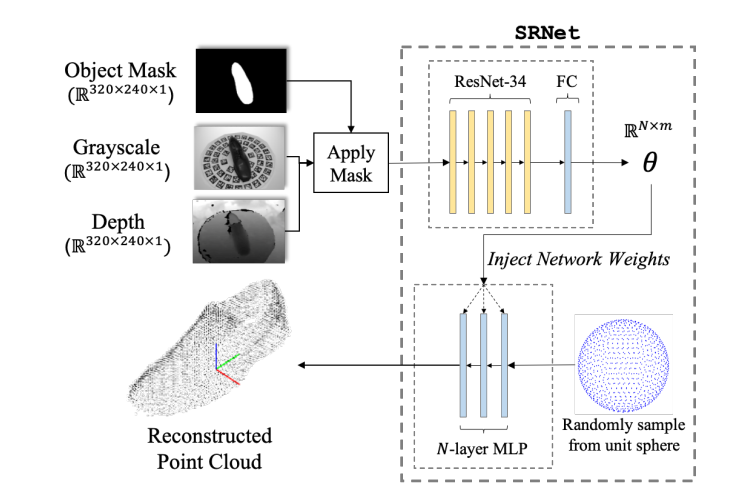
2.2 三维重建网络
使用最近的SRNet方法,进行三维重建。输入带有掩码的RGB-D图像,输出该图像对应的三维重建
2.3 抓取细化和执行
细化
它总是建议在鞋的左侧进行抓取,即使在图像中只有右侧可见,如图5所示。在这些情况下,GPNet必须“猜测”一个合适的位置,而且它的准确性往往低于抓取一个可见的点。
根据所提出的抓取建议姿态,选择点云中最接近抓取点的点,并将其位置设置为该点的坐标,保持其方向不变,对其进行细化,得到细化后的抓取建议姿态。下图提供了一个说明性的示例。通过这种投影操作来细化抓取,可以提高整个系统的精度,并在后续的抓取实验中进行验证,证明了该操作可以获得更好的性能。

执行
当对机器人执行抓握时,命令握把首先移动到离抓握点(沿着握把轴)后20厘米处的偏移点,然后移动到抓握点并关闭其手指。
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!