目录
Xie, Zhanteng, and Philip Dames. "Drl-vo: Learning to navigate through crowded dynamic scenes using velocity obstacles." IEEE Transactions on Robotics (2023). Temple University PDF
1. 概述
本文提出了一种新颖的基于学习的控制策略,对新环境具有很强的泛化能力,使移动机器人能够在充满静态障碍物和密集行人的空间中自主导航。该策略在强化学习设置中进行训练,使用包含基于速度障碍的新项的奖励函数来引导机器人主动避开行人并向目标移动。
贡献点:
- 创建了一种新的数据表示组合,用于基于神经网络的控制策略的输入,使用了短时间的池化激光雷达数据、附近行人的当前运动学和一个子目标点。
- 应用速度障碍理论为DRL框架创建一个新的奖励函数,鼓励机器人主动避免碰撞。
- 在多个模拟的3D环境中对导航性能进行了验证和演示
- 证明了该策略,只在单一人群规模的单一模拟环境中训练,可以直接在未知环境中的真实世界机器人上使用,包括在圣殿校园的室内和室外位置,以及不同的人群密度,而无需任何重新训练
- 证明了该控制策略在高度约束的静态环境中和不同的机器人平台上有效地工作,而不需要任何再训练。
2. 方法
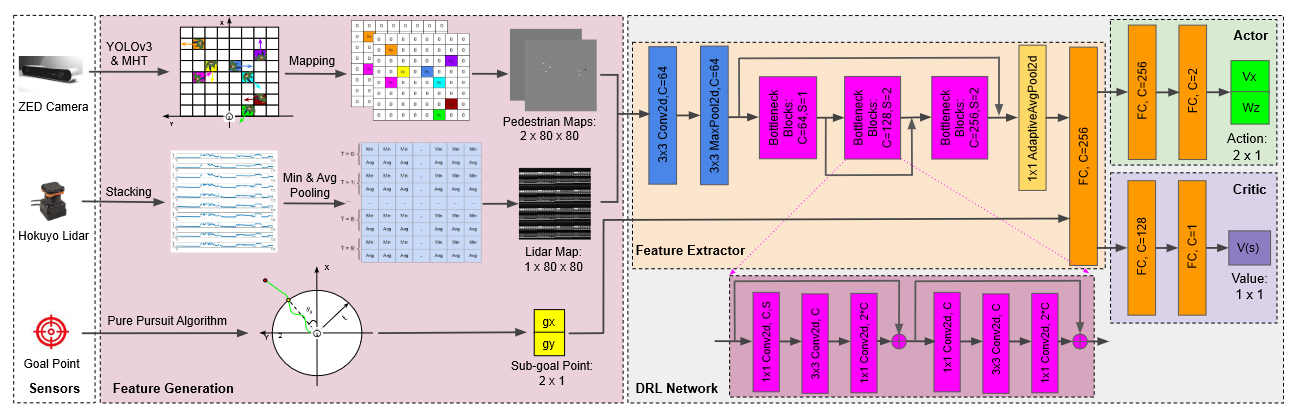
DRL网络由四个模块组成:特征生成、特征提取器、执行器和评论者
数据:ZED相机、雷达数据、子目标点
2.1 观察空间
使用部分观测值,由3个预处理组件组成:激光雷达历史( )、行人运动学( )和子目标位置( )。
所有观测中的数据都在机器人的局部参考坐标系中表达。这使得该方法对机器人在全局参考框架下的定位误差具有鲁棒性,这种情况在密集度高的动态环境中发生的频率更高,因为机器人定位的静止路标更少。相对数据更自然地用于规划目的,因为在密集的人群中导航更多的是随着交通的流动,而不是满足一些绝对速度约束。
这项前期工作的一个关键特征是使用了手工制作的中间特征,能够人为设置控制策略的大小。
1)行人运动学
提出了简单的行人运动地图表示同时编码了检测到的行人的位置和速度信息。
2)雷达历史数据
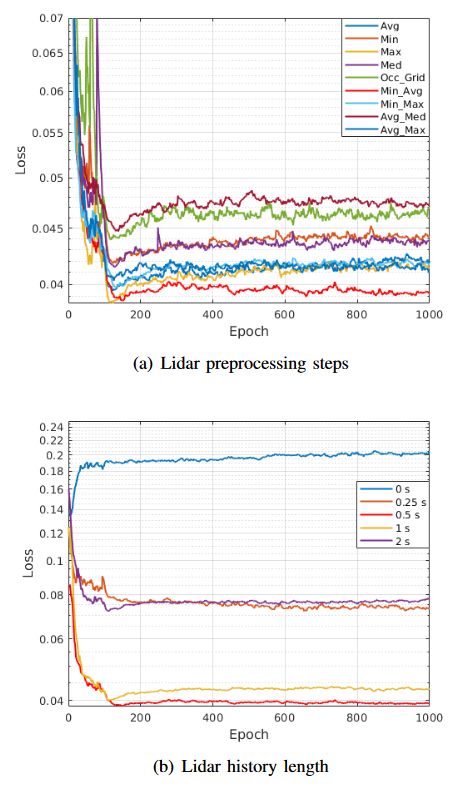
激光雷达数据由历史0.5 s的数据(即10次扫描)组成,其中对每次扫描采用最小和平均池化的组合。
最小和平均池化的组合方式,以及历史数据的时间都是对比了多种类型造成的损失后,选取的最佳组合
3)目标位置
机器人需要知道目标的相对位置。将机器人与最终目标之间划分为子目标进行移动,使得机器人可以通过复杂的、非凸的环境。
4)归一化
在将所有观测数据输入控制策略网络之前,使用Max - Abs缩放程序将所有观测数据标准化到
2.2 动作空间
DRL控制策略中的动作有两项,分别是局部机器人框架中的前向( )和旋转( )速度。
使用Max - Abs缩放程序将动作空间标准化为
2.3 网络架构
对比了两类架构:
- 第一种称为Middle,将输入端的行人运动学和激光雷达数据融合到特征提取器块中
- 第二种称为Late,将所有数据融合到特征提取器块输出之前。

如表1所示,Middle网络约为Late网络结构规模的一半,其处理速度提高了近一倍,并获得了略好的回归性能,具有更小的均方根误差( RMSE )和解释方差比( EVA )。最终决定采取Middle网络进行实验。
所用架构的核心之处:使用手工设计的特征作为中间表示,非常像传统的基于模型的算法,而不是像基于学习的算法中典型的学习特征。
2.4 奖励函数
强化学习方法的一个本质问题是如何设计一个好的奖励函数来引导智能体学习想要的行为。导航问题具有两个关键:
- 如何快速找到目标
- 如何安全避开障碍
其中,奖励朝着目标前进,惩罚被动接近或与障碍物碰撞,惩罚快速改变方向,奖励主动转向避开障碍物并指向子目标。

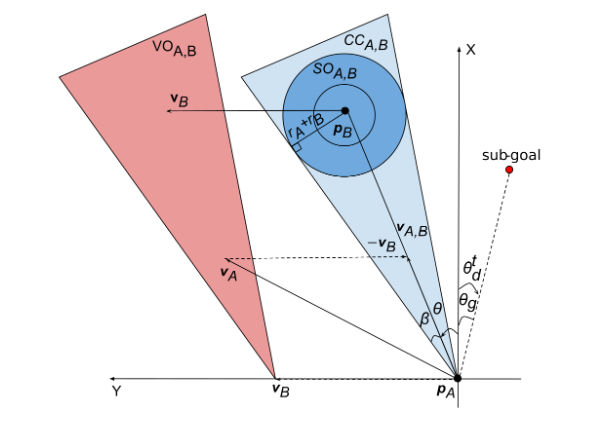
提出碰撞锥的概念,也就是先通过一个“追击问题”的概念,判断行人和机器人以各自当前的速度继续前进是否会发生相撞。再由碰撞锥和行人速度做一个明可夫斯基向量和,求出一个速度障碍锥,也就是当机器人的速度进入到速度障碍锥里时,则一定会相撞。通过这种数学的方式,快速进行避障判断。
2.5 深度强化学习算法
使用PPO算法训练DRL网络
3. 实验
实验环境:Gazebo仿真环境。Lobby有两种配置,分别为34个行人和5 ~ 55个(采样间隔10 )行人。Autolab、Cumberland、Freiburg和Square只有一种配置,25 - 35个(采样间隔10 )行人。
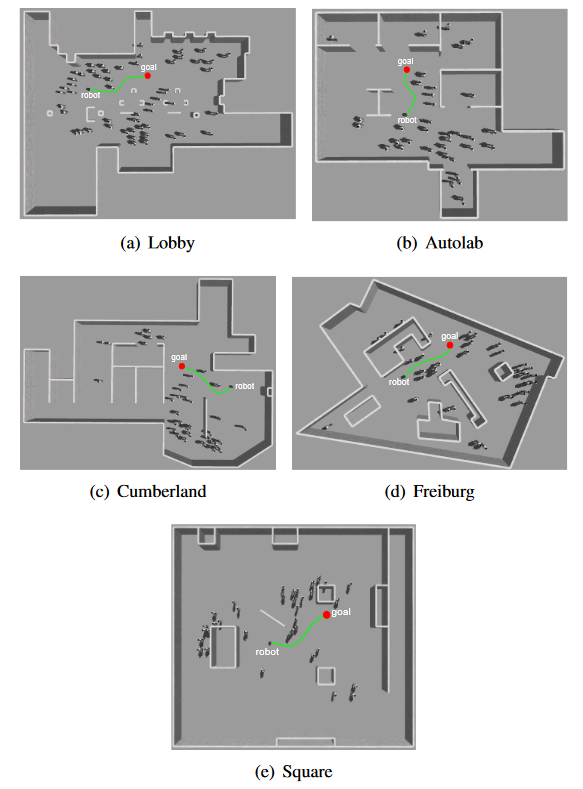
仿真环境和真实环境的效果图:
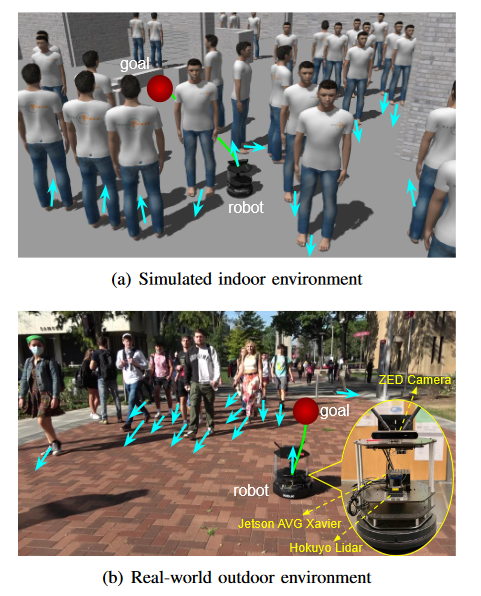
实验结果:
分析了不同人群密度下的导航效果、相同密度的不同环境导航效果,并多次进行了真机实验
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!