目录
heng, Zhuoqi, Chao Cao, and Jia Pan. "A hierarchical approach for mobile robot exploration in pedestrian crowd." IEEE Robotics and Automation Letters 7.1 (2021): 175-182. 新加坡管理大学 PDF
1. 摘要
动态物体给无碰撞导航和精确的定位/地图创建带来了巨大的挑战,这可能会降低机器人的安全性和探索性能。
该方法的中心思想:结合局部和全局信息,以确保机器人在探索过程中的安全和效率
运行速度和映射质量这两个相互冲突的目标影响着整体的探索性能,那么权衡探索效率和映射质量这两个方面,就成为了一个具有挑战性的问题。
探索过程中的三个需要考虑的因素:
-
探测安全要求机器人能够避免与行人或静态障碍物发生碰撞。
-
探索精度通过重构地图的质量和机器人在导航过程中的相关定位误差来衡量。
-
探索效率要求机器人能够在可能的情况下避免对人群流动的阻碍或采取比必要时更长的绕行路径。
创新点:
- 设计分层的自主探索规划器,在全局地图上使用基于旅行商问题( Travel-Salesman Problem,TSP )的规划器确定探索路线,在局部地图上使用基于下一最佳视角( Next-Best-View,NBV )的规划器细化探索路径。
- 基于优化后的分层探索策略,嵌入基于RL的避碰算法,保证机器人通过人群安全高效地执行导航任务
- 避碰控制器还隐式地对机器人周围的人群流量分布进行局部建模,以最大限度地减少机器人和人群之间的相互干扰,这不仅提高了探索效率,而且在建图和定位方面都提高了成功率和准确性。
**结论:**它不仅在探索效率方面优于现有方法,而且在定位和映射精度方面也优于现有方法
2. 方法
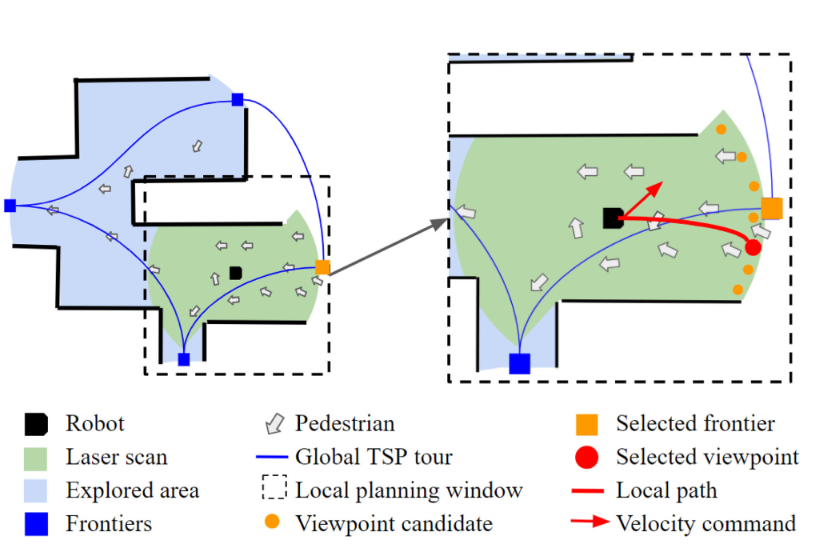
整体思路:
- 首先,被探测的部分环境以占有率栅格地图的形式被一个全局TSP规划器使用,以选择一个粗略的全局目标进行进一步的探索。
- 接下来,机器人将关注其邻域区域内指向粗略全局目标的一个子空间,并对该子空间进行划分以进行更细致的视点选择,即选择附近一个未被探索的航路点作为下一步探索的中间或局部目标。
- 最后,基于RL的控制器用于驱动机器人通过密集的人群,并高效安全地到达局部目标
2.1 全局规划器
基于TSP的全局规划用于解决覆盖探索空间的全局粗略轨迹,表示为2D占用栅格地图M。
值得注意的是,这些最短路径可以通过任何其他路径规划算法来计算,例如D *算法,这在动态场景中可以更有效。不同路径规划算法的影响在这里是微不足道的,因为路径是在小规模和低分辨率地图上生成的,它们不是机器人执行的实际路径,而只是用于确定图G中的边权重。
2.2 局部规划器
全局规划结果可以用于根据计算的TSP轨迹指定对未探索的子区域的访问顺序,但无法分配路径点或指定机器人行驶的路径。为此,我们使用NBV选择算法从粗略的全局目标中精化一个航迹点,并使用算法规划到该航迹点的可行路径。
一个典型的NBV选择方法[包括三个步骤:
- 在全局目标点周围随机采样n个候选视点
- 根据评价函数对每个候选视点进行评分,将得分最高的候选视点作为下一个目标点
- 将glocal和机器人位置p,以及二者的连线发送给基于RL的导航模块,进行导航
2.3 基于RL的控制器
考虑到全局和局部规划器对探索的有效指导,密集人群中自主探索的下一个挑战是如何在执行规划器的高效探索指导的同时,保证安全稳定的避撞行为。
在每个规划时间步t,机器人接收一个局部观测值,并决定一个速度指令,将机器人引向给定的临时目标位置。
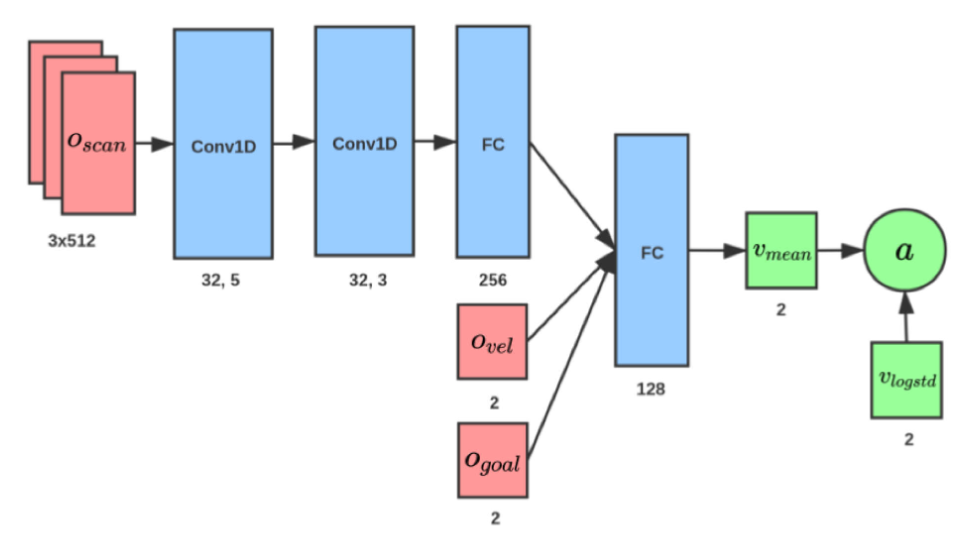
过程:从策略网络学习到的策略π中采样动作,该策略网络包括两个卷积层和一个从输入扫描数据中提取特征的全连接层,如图2所示。将提取到的激光扫描特征与和进行拼接,并送入全连接层。网络的输出为机器人的无碰撞速度指令v和ω,如图1中红色箭头所示。基于RL的避碰算法使用基于Actor - Critic的PPO算法在一组具有简单静态障碍物和具有r的小人群的场景中进行训练。
3. 实验
从两个方面进行对比实验:
- 是否采用分层架构:
- 不采用:NF、NF_RL
- 采用:HNF、HNF_RL、HTSP、HTSP_RL
- 是否采用基于强化学习的避障算法
- 不采用:NF、HNF、HTSP
- 采用:NF_RL、HNF_RL、HTSP_RL
实验环境:
- 使用两个模拟器Gazebo [23]和Menge [24],其中Gazebo模拟机器人和静态障碍物,而Menge负责生成机器人的运动场景中的人群
- 使用 Turtlebot2 作为移动机器人平台,它安装了 Rplidar A2 传感器
实验结果:
- 使用分层算法的效果优于不分层算法
- 使用RL模块的算法效果优于不使用RL的算法
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!