目录
Bauer C, Bauer D, Allaire A, et al. Learning to Navigate by Pushing[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 171-177. 卡内基梅隆大学 PDF
1. 摘要
思路:人类能够通过大量的动态交互,来让环境满足某种状态,比如说通过跳跃、攀爬达到翻越障碍物的目的。而传统探索中,机器人只能绕过障碍进行探索,因此尝试让机器人与环境进行交互,推动可移动障碍物。
贡献点:
- 动态推进式机器人运动:提出了一种利用机器人的双臂与障碍物接触来实现动态运动的方法,可以让机器人在杂乱的环境中更自由、灵活和快速地移动。
- 基于反射的控制器:设计了一种分层的控制器结构,由一个高层控制器根据当前的观测状态切换不同的反射控制器,每个反射控制器通过优化参数来产生特定的动态运动。
- 构建PushBot平台:构建了一个悬浮式双臂机器人平台(PushBot),并将模拟中学习到的控制策略直接迁移到真实机器人上,展示了成功完成推进任务的能力。
与之前的工作相比,该方法不依赖于周期性的运动、复杂的机器人和接触动力学模型、大量的手动调整。
2. 方法

该方法在特定的观察下,由高级控制器不断切换优化的低级控制器,每个控制器都是针对单独的任务,例如前推反射。这种方法还可以识别相似行为的连续簇,也就是运动家族(彩色区域)。这样可以直接将不同的推动运动从仿真转移到真实机器人上,而无需进一步的重新训练。下方显示了向右、向左和向中心推动的时间序列。
2.1 机器人状态和动作空间
- 定义了机器人的状态:
分别为:速度、关节角度、末端执行器的接触状态、相对于目标的位置和朝向、最近障碍物的距离和相对朝向
- 定义了动作空间:
分别为:目标角度、手臂关节PD控制器的增益
- 定义了一个基于距离的奖励函数:它根据机器人手臂末端与目标位置之间的距离来计算奖励值。当机器人手臂末端与目标位置越接近时,奖励值就越大;反之,当机器人手臂末端与目标位置越远时,奖励值就越小。
2.2 推进运动的建模
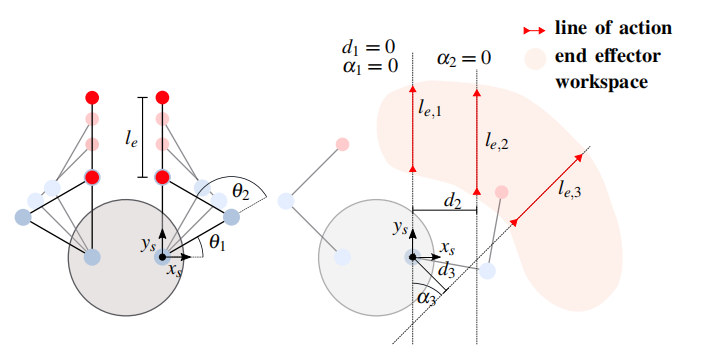
根据人类推进运动的直觉,提出了一种反射控制器,将机器人的末端执行器限制在沿着固定方向的直线运动,通过调节推进的距离和速度来控制推进的强度。
左图为直线推动,右图为沿不同动作线的推动示例。沿动作线将机械臂结构划分为,0表示完全缩回,1表示完全伸出。
2.3 基于反射的控制器用于推进任务

提出一种分层的控制器结构,由一个高层控制器根据当前的观测状态切换不同的反射控制器。每个反射控制器通过优化参数来产生特定的动态运动。
- 高层控制器:通过有限状态机和明确的转换规则来实现切换机制(例如,如果在两端执行器发生接触,打开前推反射控制器)
- 低层反射控制器:在被高层控制器触发后,会经历两个阶段:配置阶段和激活阶段。在配置阶段,根据当前的观测状态选择合适的参数,包括PD控制器的增益、运动设定点、时间步长和运动方向;在激活阶段,执行特定的动态运动。这种方法可以让机器人通过与障碍物接触来实现动态推进运动。
2.4 学习反射控制器
目标:是找到一个配置策略,这样给定在配置时间(当反射控制器被触发时)的当前状态,由控制器创建一个动态运动,加速机器人躯干向目标前进。
定义优化状态:
- 初始化网格空间
- 将可能的配置状态 的空间组织成一个离散的空间 ,这样每个点 代表一个不同的 值。在推动任务设置中,不同的 值对应于不同的初始条件
- 每个网格点 ,寻找最优配置 ,最大化任务奖励
- 使用黑箱优化算法(CMA-ES)和局部搜索算法(L-BFGS-B)来寻找最优解。首先在离散的状态空间中进行全局搜索,找到初始解,然后在邻近的状态点进行局部搜索,使用初始解作为起点。如果局部搜索不收敛,则重新进行全局搜索,寻找新的局部最优解。通过这种迭代搜索的方法,可以找到不同状态下的最优反射控制器配置。
- 优化迭代过程
- 使用k-最近邻回归模型来预测给定状态下合适的推进配置
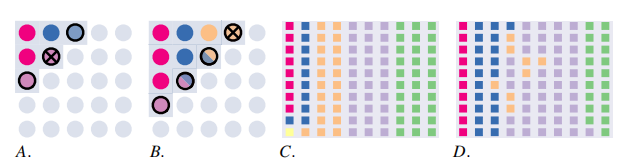
颜色相同表示属于同一个运动家族,即相似行为
3. 实验
**仿真环境:**在Box2D仿真引擎中搭建了一个2D仿真环境,并建立了一个简单的双臂平面机器人模型
实验类型:
- 静态1D推动:紧挨着放置机器人和障碍,沿固定x轴推动
- 1D推动:机器人向障碍物移动,沿固定x轴推动
- 2D推动:机器人向障碍物移动,沿斜角推动
**基线模型:**PPO
实验结果:
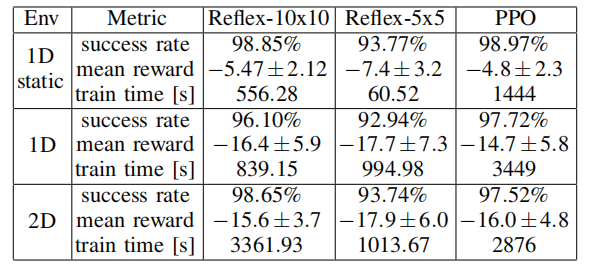
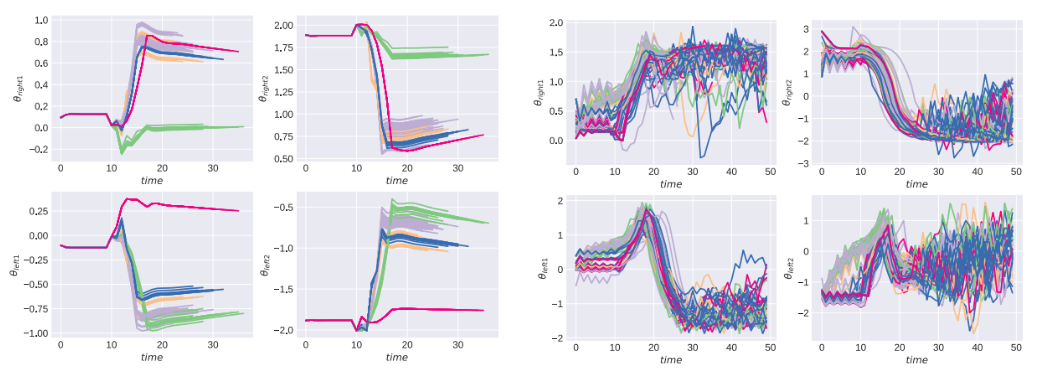
左:反射控制器 右:PPO
在成功率上相似,但该论文的方法产生的轨迹更加平滑
真机实验:
构建了一个悬浮式机器人平台(PushBot),展示了如何直接将仿真中学习到的控制策略转移到真实机器人上,完成不同方向的推动任务。
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!