目录
Xu Y, Zhang Z, Yu J, et al. A framework to co-optimize robot exploration and task planning in unknown environments[J]. IEEE Robotics and Automation Letters, 2022, 7(4): 12283-12290. 清华大学 PDF
1. 摘要
在传统的方法中,代理首先探索环境来实例化一个完整的规划域,然后调用一个规划器来计划和执行高级操作。由于探索和规划两个过程是顺序执行,且涉及到许多重复的状态和操作,导致任务执行效率低下。
贡献点:
- 提出了一种优化机器人探索和任务规划的框架:让机器人在未知环境中能够同时进行探索和符号规划,而不是按顺序进行,从而提高了任务执行效率。
- 设计了一种将探索和规划分解为子任务的方法:将这两个独立的过程进行统一。并利用一个基于价值的调度策略来选择合适的子任务。
- 在真实感模拟器中评估框架性能:在AI2-THOR模拟器中,对三种复杂的家庭任务进行了实验,与现有方法相比,提高了约29%的执行效率。

传统方法:需要19步,探索与规划分离,需要先经过探索找到苹果和盘子,才能进行规划,将苹果放到盘子上
该方法:需要9步,探索与规划结合,在探索过程中发现苹果并拿起,再发现盘子,将苹果放到盘子上
2. 方法
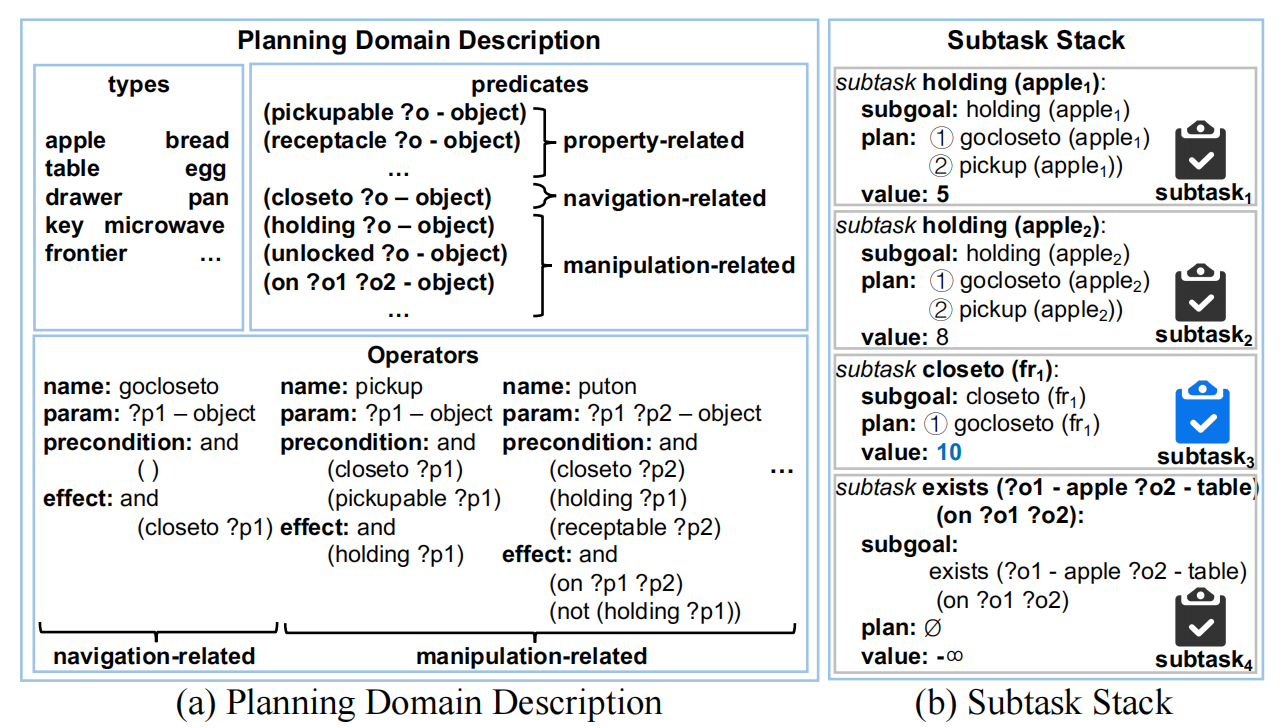
(a)类别与谓词,谓词分为属性相关、导航相关、操作相关,(b)为子任务堆栈示例
2.1 框架
框架由五个模块组成:感知模块、反向规划图生成器、子任务管理器、基于价值的调度器和子任务编译器。
- 在执行任务之前,反向规划图生成器根据用户指定的任务目标生成一个反向规划图,用于提取必须经历的中间状态作为子任务的子目标。
- 在执行任务期间,感知模块负责从原始传感数据中提取地图和状态信息
- 子任务管理器负责将原本独立的探索和规划过程分解为多个具有统一结构的子任务,并根据当前环境信息对子目标进行实例化
- 基于价值的调度器负责在每个状态下选择最优的子任务
- 子任务编译器负责将选中的子任务编译为低级控制命令,让机器人可以在环境中执行。
2.2 感知和子任务编译器
感知模块:从原始传感数据中提取地图和状态信息,在每一步更新实体对象、状态信息、占用地图
子任务编译器:将选中的子任务编译为低级控制命令。对于导航相关的操作符,使用A*算法进行路径规划,对于操作相关的操作符,使用模拟器提供的API来与物体交互。
2.3 反向规划图生成器
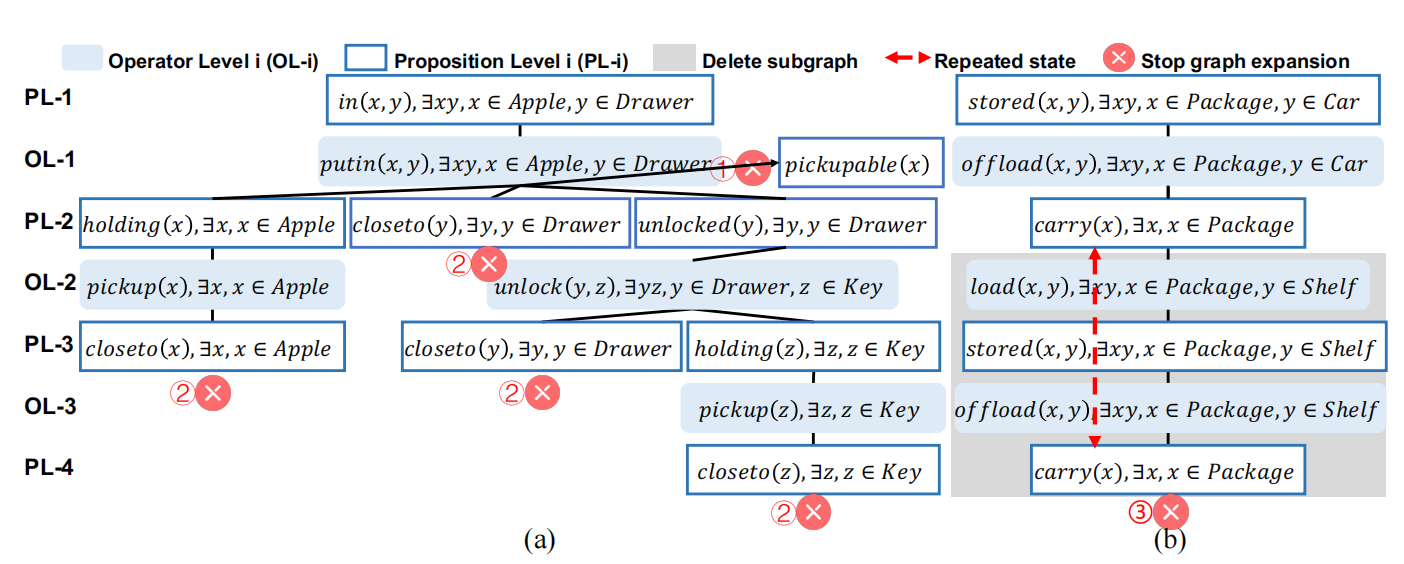
根据指定的任务目标生成反向规划图的示例:将苹果放入抽屉、在车上放一个包
该模块的作用是用于提取必须经历的中间状态作为子任务的子目标。反向规划图是一个有向分层图,包含两种类型的节点(命题节点和操作节点)和两种类型的边(前提边和效果边)。反向规划图按层生成,并使用三种终止规则来限制图的扩展。
2.4 子任务管理器
介绍了如何将探索和规划分解为多个具有统一结构的子任务,并根据当前环境信息对子目标进行实例化。一个子任务包含三个属性:一个用谓词表示的子目标、一个实现子目标的计划和一个价值。
探索子任务:使用基于边界点的方法来生成子目标、计划和价值;例如在探索过程中,谓词域中对应的导航谓词是“closeto”,当前的边界点是“fr”,可生成子目标“closeto(fr)”。由此调用规划器来生成规划和对应价值。
规划子任务:代理无法直接到达最终目标,必须经过一些中间状态。因此使用反向规划图来提取有效的中间状态作为子目标,并用规划器来生成计划和价值。
2.5 基于价值函数选择子任务的方法
介绍了如何定义一个价值函数,综合考虑探索带来的信息增益、规划带来的任务奖励和执行代价,从而在每个状态下选择最优的子任务。
:执行子任务需要的步骤
:潜在的信息增益,即在子任务执行期间所覆盖的未映射区域的体积(探索)
:对应于一个子任务对完成最终目标的贡献所产生的奖励收益(任务规划)
和分别侧重于探索和规划,适当的取值使代理能够平衡探索和规划任务。
价值函数使得每个子任务在栈中都能计算出其对应的价值,而基于价值的调度器负责选择具有最高价值的子任务。通过最大化提出的价值函数,该论文以统一的方式优化了机器人探索和任务规划。
3. 实验
在模拟器中评估框架性能:在AI2-THOR模拟器中,对三种复杂的家庭任务进行了实验,分别是将一个物体放在另一个物体上(On),将一个物体放入一个锁着的物体中(In),和将一个物体放入一个微波炉中并加热(Cook)。实验设置了不同的场景大小和目标物体类型,并与现有方法进行了对比。
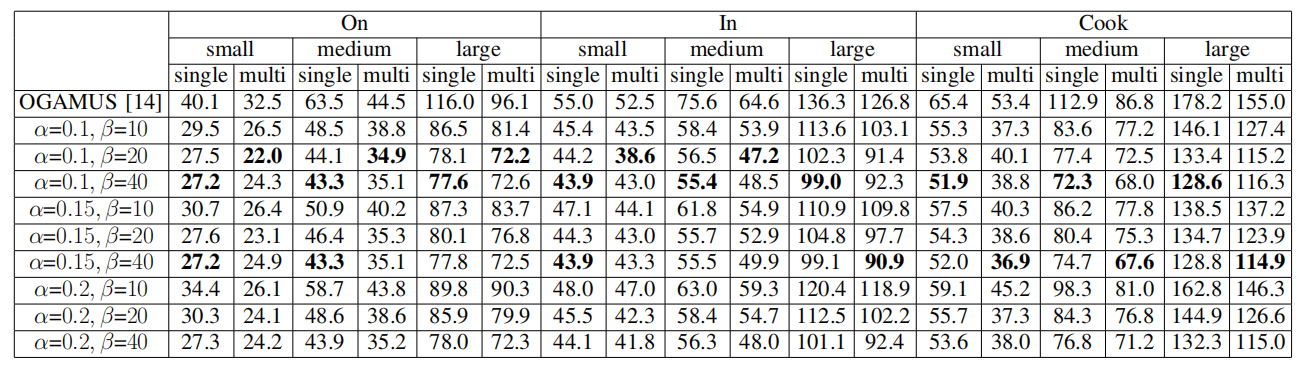
该框架在所有任务和场景中都显著提高了任务执行效率,平均提高了约29%。
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!