目录
Lu, Yuhao, et al. "VL-Grasp: a 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes." arXiv preprint arXiv:2308.00640 (2023). PDF
1. 摘要
任务定义: 机器人抓取由人类语言指令指定的目标物体,称为视觉语言抓取
- 找到自然语言指定的目标
- 预测如何抓取并执行
当前方法存在的三个问题:
- 视觉接地数据集缺乏数据内容和抓取的关联性
- 普通数据集缺乏适合抓取的物体和多角度观察
- 缺乏模糊样本,即一个图像中存在多个相同类型的类别
创新点:
- 提出了一种新的交互式抓取策略:VL-Grasp。VL-Grasp创新地结合视觉接地和6-Dof抓取姿势检测方法来处理交互式抓取任务
- 设计了新的视觉接地数据集,RoboRefIt,用于机器人视觉语言推理
- 设计了一个点云过滤器模块,提高了在复杂场景中的抓取成功率。
2. 数据集
该RoboRefIt包含10,872张RGB-D图像和50,758个参考表达式。所有这些图像都是在真实的室内场景中收集的,涉及66个物体类别和187个不同的场景。有5636张图像出现了多个相同类型的物体。RoboRefIt注释了两种类型的标签: 2D边界框和分割掩码。
2.1 数据收集
从GraspNet-1Billion数据集中选取了23类对象,自行选取43类对象,共66个物体类别
187个不同的日常生活场景,每个场景中选择3-10个对象
在多个场景中设置两到三个相同类别对象,增加模糊样本的复杂性
为场景图像中的对象创建唯一的语义描述:
2.2 数据标注
请注释专家对数据集中的图像打标签,再经过三轮审核
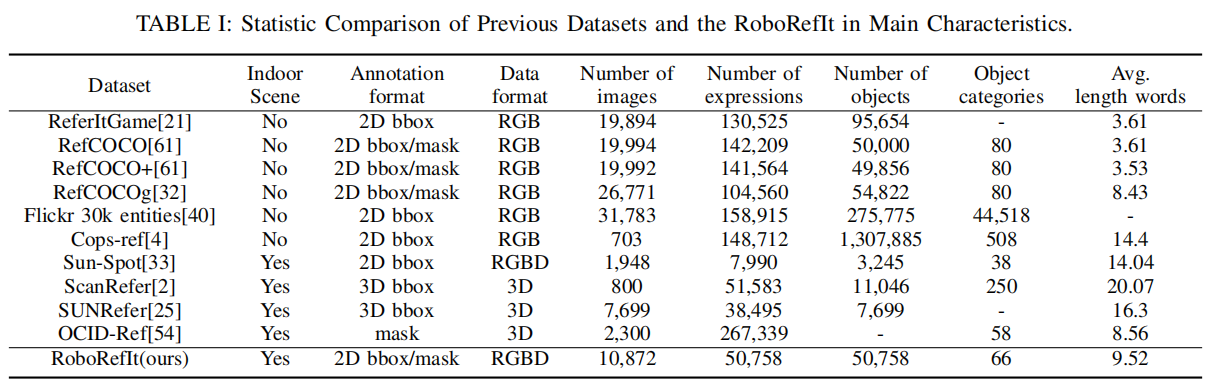
2.3 与其他数据集对比
优势:
- 与机器人的内容相关性强(室内场景、可抓对象)
- 注释和图像数据的格式
- 表达和图像的比例
- 对象的多样性
- 模糊样本
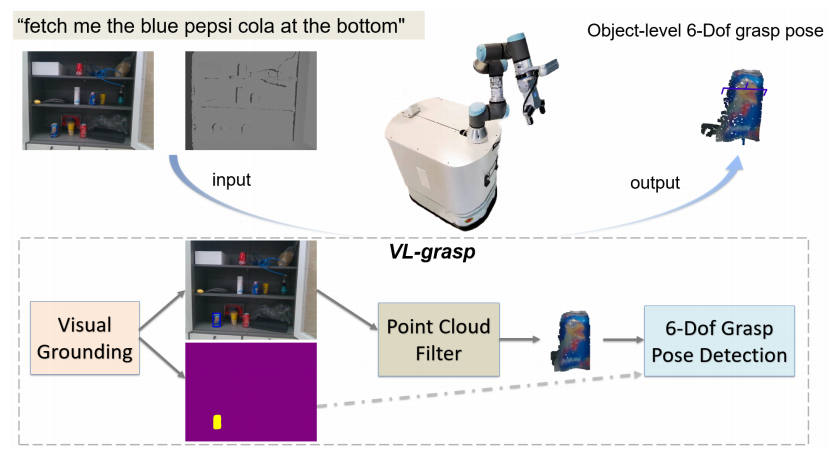
3. 方法
提出了基于两阶段的策略,称为VL-Grasp
- 第一阶段输入RGB图像和自然语言命令,并输出包括2D边界框和分割掩模的目标对象位置结果
- 第二阶段输入结果和深度图像,并输出最终抓握配置。
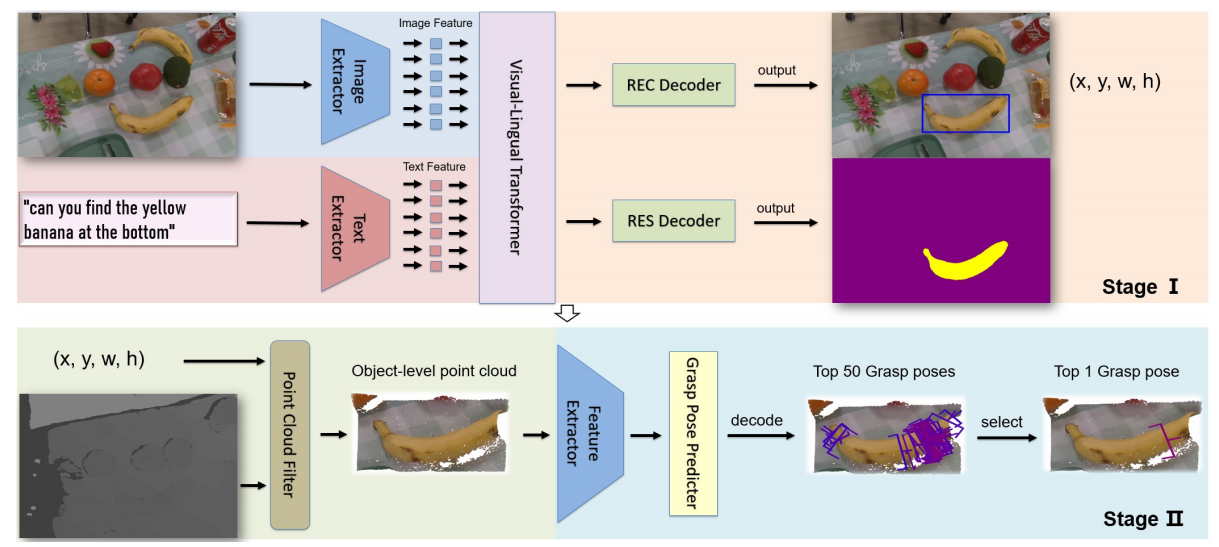
3.1 视觉接地网络
将第一个阶段分为三步:提取特征、融合特征、获取边界框和分割掩码
- 提取特征:使用语言模型BERT作为文本提取器来提取自然语言命令的文本特征
- 融合特征:使用视觉语言transformer通过跨模态融合机制,融合视觉特征和语言特征
- 分割掩码:根据REC和RES解码器分别预测边界框和分割掩码。
REC:对象检测,显示bounding box
RES:对象分割,突出显示目标对象

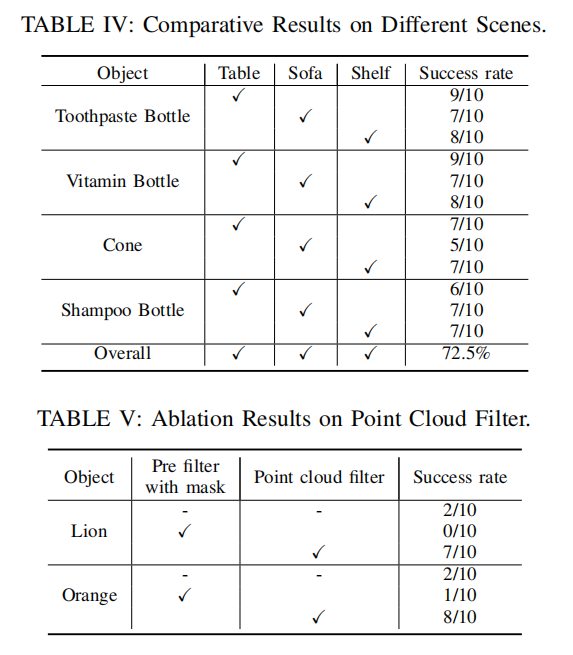
3.2 点云过滤
在第二阶段,使用展开的边界框裁剪深度图像,再将裁剪后的深度图像转化为具有相机内部参数的单视点云,也可以称为对象级点云
扩展操作使用尺寸参数扩展边界框的比例,并保留更完整的对象几何信息和边缘背景几何信息。
点云过滤能够提高抓取的成功率
3.3 6自由度抓取的姿态检测网络
根据点云过滤输出的对象级点云,抓握姿态预测器输出不同分辨率的抓握特征
低分辨率有丰富的语义信息,预测抓握姿态
高分辨率有丰富的空间信息,用于预测旋转方向和深度,计算置信度。选择最高置信度的抓握姿态
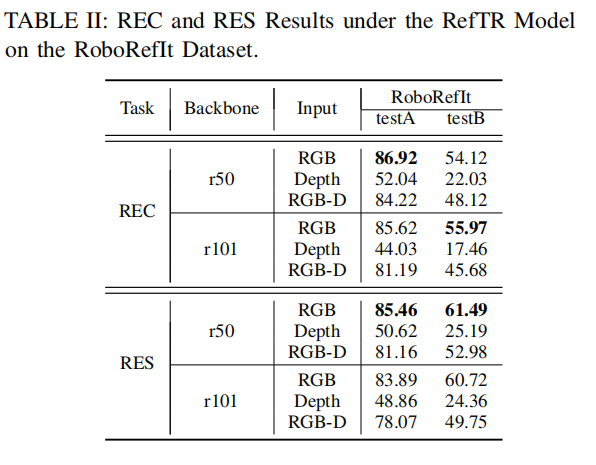
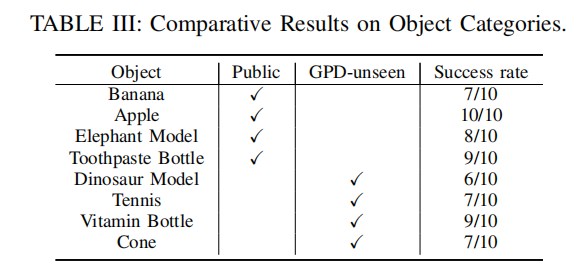
4. 实验
在仿真环境中对RES和REC任务进行了评估
在真实环境中测试了VL-Grasp的泛化能力、不同场景的适应能力;通过消融实验表示了点云过滤模块对抓取成功率的重要影响
本文作者:southyang
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!